
1. 인덱스 템플릿
인덱스 템플릿은 주로 설정이 동일한 복수의 인덱스를 만들 때 사용한다.
즉, 말 그대로 템플릿이다. 템플릿에 맞춰, 인덱스를 찍어낸다는 것.
이 템플릿을 만들어보...기 전에 한번 템플릿이 어떤게 있는지 확인해보자.

그냥 _index_template만 입력하면 모든 인덱스 템플릿을 검색하고, 뒤에 ilm*을 추가하면 특정 인덱스(ilm으로 시작하는) 템플릿을 확인할 수 있다.
그래서 ilm-history라는 인덱스가 나온 것이다.
이제 템플릿을 하나 만들어보자.
PUT _index_template/test_template
{
"index_patterns": ["test_*"],
"priority": 1,
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings":{
"properties":{
"name": {"type": "text"},
"age" : {"type": "short"},
"gender": {"type": "keyword"}
}
}
}
}
test_template라는 이름의 템플릿을 생성한다.
인덱스 템플릿의 파라미터는 아래와 같다.
- index_patterns: 새로 만들어지는 인덱스 중에 인덱스 이름이 인덱스 패턴과 매칭되는 경우 이 템플릿이 적용됨. 여기서는 test_로 시작되는 이름을 가진 인덱스들은 모두 test_templates에 있는 매핑, 세팅 등이 적용된다.
- priority: 인덱스 생성 시 이름에 매칭되는 템플릿들이 둘 이상일 때 템플릿이 적용되는 우선순위를 정할 수 있다. 숫자가 가장 높은 템플릿이 먼저 적용된다. 우선순위가 겹치면 어떻게 되냐? 우선순위가 겹치지 않게 설정하는 게 정답이다.
- template: 새로 생성되는 인덱스에 적용되는 settings, mappings 같은 인덱스 설정을 정의한다.
이제 이 템플릿을 적용해보자.
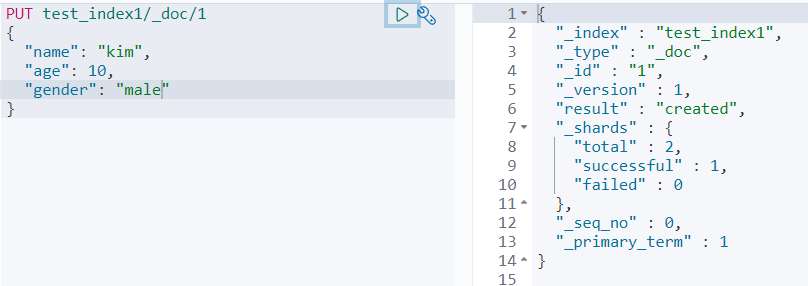
test_index1이라는 인덱스에 템플릿이 잘 적용되었는지 확인해보자.

잘 되었다!
다음으로, age에 아예 텍스트를 넣어서 인덱스를 생성해보자.

숫자형 데이터에 문자형 데이터가 들어왔다면서 에러가 발생한다.
이처럼, 템플릿은 사용자 실수를 막아주고 반복적인 작업을 줄여준다.
실제로 특정 날짜 / 시간 별로 인덱스를 만드는 경우나 로그스태시, 비츠 같은 데이터 수집 툴에서 엘라스틱서치로 데이터를 보낼 때 템플릿을 이용해 인덱스를 생성하는 경우가 많다.
이제 템플릿을 알았으니, 삭제해보자.

마지막으로 다이나믹 템플릿에 대해서 짧게 짚고 넘어가자.
다이나믹 템플릿은 말 그대로, 매핑을 엘라스틱서치가 알아서 지정하는 템플릿이다.
다이나믹 매핑과 뭐가 다르냐?고 묻는다면, 어느정도 사용자의 의도가 개입된다고 볼 수 있다.
말로 하니까 이상한데, 아래 예시를 보면 바로 알 수 있다.

dynamic_index1이라는 인덱스는 다이나믹 템플릿을 사용한다. 안의 my_string_fields는 그냥 임의로 정한 이름이니까 무시하고, 그 밑으로 2개의 설정이 있다.
match_mapping_type은 조건문 혹은 매핑 트리거다. 즉, "string" 타입 데이터가 있으면 조건에 만족한다.
mapping은 말 그대로 어떻게 매핑하느냐다.
이를 토대로 해석하면, "string 타입 데이터를 keyword로 매핑한다"라고 명시해주는 것이다.
자, 한번 도큐먼트를 인덱싱해 어떻게 되는지 확인해보자.

원래대로라면 name 필드는 'text' 타입이 될 운명이었다. 그러나 다이나믹 템플릿에 의해서 string 형태(name field)를 keyword 타입으로 정의해주었다.
다이나믹 템플릿은 이런 것도 가능하다.

match는 조건에 맞는 경우 mapping에 포함시키고, unmatch는 조건에 맞는 경우 mapping에서 제외시킨다.
뭔가 싶을수도 있지만, 아래 예시를 보면 바로 이해할 것이다.

long_num은 타입이 long으로, long_text는 타입이 text로 정의되었다.
즉, 다이나믹 템플릿 조건문에 의해 타입이 달라진 것이다.
이런것도 있다는 것만 알면 될 것 같다.
2. 분석기
엘라스틱서치에서 양질의 검색 결과를 얻기 위해서는 문자열을 나누는 기준이 중요하며, 이를 지원하기 위해서 엘라스틱 서치는 캐릭터 필터, 토크나이저, 토큰 필터로 구정되어 있는 분석기 모듈을 가지고 있다,

분석기에는 반드시 하나의 토크나이저가 포함되야 하며, 캐릭터 필터와 토큰 필터는 옵션이다.
참고로 토큰, 용어(Term)은 엄연히 다른 개념이다.
토큰은 토크나이저 단계에서 분리된 단어를, 용어는 정제되어 인덱스에 저장되는 상태를 의미한다.
즉, 토큰은 분석기 내부에서 일시적으로 존재하는 것이고, 인덱싱되어 검색에 사용되는 단위는 용어다.
일단, 분석기 모듈의 구성은 아래와 같다.
- 캐릭터 필터: 입력받은 문자열을 변경하거나 불필요한 문자들을 제거한다.
- 토크나이저: 문자열을 토큰으로 분리한다. 분리할 때 토큰의 순서나 시작, 끝 위치도 기록한다.
- 토큰 필터: 분리된 토큰들의 필터 작업을 한다. 대소문자 구분, 형태소 분석 등의 작업이 가능하다.
3. 역인덱싱
우선 역인덱싱이 뭔지를 알고 넘어가야 한다.
문자열을 토큰화하고 인덱싱하는 걸 역인덱싱이라고 한다.
예를 들어 아래의 두 문서에 각각의 문장을 역인덱스 테이블로 정리해보자.
문서 1: I Love Cute Dog.
문서 2: the 10 most loving dog breeds.
| Term | ID |
| breeds | 2 |
| cute | 1 |
| dog | 1, 2 |
| i | 1 |
이렇게 되면, dog를 검색하면 역인덱스 테이블을 참고해 문서 1,2번에 dog라는 용어가 있음을 알 수 있다.
그러면, 분석기 API를 한번 사용해보자.

이전에 사용한 _analyze와 조금 결과가 다르다. the, 10가 삭제되었다.
"stop" 분석기(가 포함한 stop 필터)는 불용어를 처리하기 때문이다.
즉, 분석기마다 다른 분석을 수행한다.
- standard: 기본 분석기. 영문법을 기준으로 standard 토크나이저, lowercase 필터, stop 필터가 포함되어 있다.
- simple: 문자만 토큰화한다. 공백, 숫자, 하이픈이나 작음따옴표같은 문자는 토큰화하지 않는다. lowercase 필터는 적용
- whitespace: 공백을 기준으로 구분해 토큰화한다.
- stop: simple 분석기와 비슷하나 스톱 필터 포함.
당연히도, 토크나이저도 각기 특성이 있다.
- standard: 쉼표나 점 같은 기호를 제거, 텍스트 기반으로 토큰화
- lowercase: 모든 문자를 소문자로 변경해 토큰화
- ngram: 원문으로부터 N개의 연속된 글자 단위를 모두 토큰화한다.
- uax_url_email: url이나 email을 토큰화하는 데 강점이 있다.
ngram이 무슨 말인지 헷갈릴 수도 있는데, 다음과 같다.
예를 들어, '엘라스틱서치'라는 원문을 2gram으로 토큰화하면 [엘라, 라스, 스틱, 틱서, 서치]와 같이 연속된 2글자를 모두 추출한다. 저장공간을 많이 잡아먹는다는 단점이 있다.
4. 필터
필터는 당연히 단독으로 사용 불가능하고, 토크나이저가 있어야 한다.

아까 필터에 '캐릭터 필터'와 '토큰 필터'가 있다고 했는데, 대략 설명하자면
- 캐릭터 필터: 문자들을 전처리. HTML 문법을 제거 및 변경하거나 특정 문자가 왔을 때 다른 문자로 대체하는 일을 수행. 엘라스틱서치의 분석기는 이를 기본적으로 포함하지 않으므로, 따로 커스텀 분석기를 만들어 캐릭터 필터를 적용하는 것이 좋다.
- 토큰 필터: 토크나이저에 의해 토큰화되어 있는 문자들에 필터를 적용. 토큰들을 변경하거나 삭제하고 추가하는 작업들이 가능. 자주 사용하는 토큰 필터로 lowercase(uppercase), stemmer(영어 문법을 분석하는 필터), stop(기본 필터에서 제거하지 못하는 특정한 단어 제거 가능)
5. 커스텀 분석기
말 그대로 '사용자가 만든 분석기'다.
한번 만들어보자.
PUT customer_analyzer
{
"settings": {
"analysis": {
"filter": {
"my_stopwords":{
"type": "stop",
"stopwords": ["lions"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [],
"tokenizer": "standard",
"filter": ["lowercase","my_stopwords"]
}
}
}
}
}
- settings, analysis: 인덱스 설정(settings)에 analysis 파라미터를 추가해 필터와 분석기 생성
- my_stopwords, my_analayzer: 필터 이름과 분석기 이름
- type: custom -> 커스텀 분석기를 의미
- char_filter: 캐릭터 필터. 사용하지 않으므로 빈 리스트를 입력
- tokenizer: 토크나이저. 기본 스탠다드 토크나이저 사용
- filter: 필터, lowercase, my_stopwords 사용
- stopwords: ['lions'] -> lions 단어가 나오면 '불용어'로 처리.
마지막 줄이 핵심이다. 그러면 진짜 lions를 넣으면 불용어로 처리되는지 확인해보자.

정말로 lions가 불용어 처리되는 걸 볼 수 있다.
6. 필터 적용 순서
커스텀 분석기에서 필터를 여러 개 사용할 때 순서에도 주의해야 한다.
당연하게도, '앞에서부터' 필터가 적용된다.
filter에서 'lowercase'와 'my_stopwords' 순서를 바꿔서 실행해보자.

따라서 커스텀 분석기에 필터를 적용할 때는 필터들의 순서에 유의해야 하고, 가능하면 모든 문자를 소문자로 변환한 후 에 필터를 적용하는 것이 관례이다.
이제 이론적인 내용은 끝났고, 엘라스틱 검색을 다룰 때가 되었다.
다음에 계속!
'ElasticSearch' 카테고리의 다른 글
| 엘라스틱서치 오타 교정, 자동 완성 등 구현 (0) | 2022.11.14 |
|---|---|
| 엘라스틱서치, 검색 (0) | 2022.11.10 |
| 엘라스틱서치 기본 (0) | 2022.11.09 |
| 엘라스틱 설치 다시시도 (0) | 2022.11.09 |
| 검색 시스템과 ElasticSearch (0) | 2022.11.08 |