
한글 검색 시스템을 구현해보기 위해서, 엘라스틱서치를 공부하기로 했다.
여러 책을 찾아보다가, '엘라스틱서치 실무 가이드'라는 책을 기반으로 공부하기로 했다.
https://product.kyobobook.co.kr/detail/S000001766375
엘라스틱서치 실무 가이드 | 권택환 - 교보문고
엘라스틱서치 실무 가이드 | 이 책은 오픈소스 검색엔진의 대표 주자인 엘라스틱서치에 대한 전반적인 내용을 다룬다. 하지만 단순히 엘라스틱서치의 기능을 단편적으로만 설명하고 끝내는 것
product.kyobobook.co.kr
(이 책이다)
엘라스틱서치를 설치하기 전에, 검색 시스템에 대한 내용이 있어 정리하기로 했다.
검색 시스템 이해하기
이번 절에서는 검색엔진과 데이터베이스를 비교해본다. 먼저 검색 시스템의 등장 배경을 살펴보고 검색 시스템의 특징과 필요성을 함께 생각해보자.
우선 검색 엔진, 검색 시스템, 검색 서비스에 대한 용어를 정리했는데, 각 키워드는 다음과 같다.
- 검색 엔진(Search Engine): 광활한 웹에서 정보를 수집해 검색 결과를 제공하는 프로그램
- 검색 시스템(Search System): 검색 엔진을 기반으로 신뢰성 있는 검색 결과를 제공하기 위해 구축된 시스템을 통칭하는 용어
- 검색 서비스(Search Service): 검색 시스템을 포함해, 서비스를 제공하는 것
그러니까, 검색 엔진으로 검색 시스템을 만들고, 검색 시스템으로 검색 서비스를 만든다는 것이다.
검색 서비스 > 검색 시스템 > 검색 엔진
엘라스틱서치는 이 중 검색 엔진에 해당된다.
다음으로 검색 시스템의 구성 요소에 대해 다룬다. 크게 수집기, 스토리지, 색인기, 검색기가 있다.
- 수집기: 정보를 수집하는 프로그램. 수집기가 정보룰 수집 및 저장하면 검색 엔진이 이를 검색한다.
- 스토리지: DB에서 데이터를 저장하는 물리적인 저장소다. 검색 엔진은 색인한 데이터를 스토리지에 보관한다.
- 색인기: 수집된 데이터를 검색 가능한 구조로 가공하고 저장하는 역할을 수행. 다양한 형태소 분석기를 조합해 정보에서 의미가 있는 용어를 추출하고 검색에 유리한 역색인 구조로 데이터를 저장.
- 검색기: 사용자 질의를 입력받아 결과로 반환. 유사도 기반의 검색 순위 알고리즘으로 판단. 형태소 분석기를 기반으로 검색. 따라서 형태소 분석기에 따라서 검색 품질이 달라짐.

다음은 관계형 데이터베이스(RDBMS)와의 차이점을 다룬다.
관계형 데이터베이스도 질의와 일치하는 데이터를 찾는 역할을 수행하니까.
다만, 데이터베이스는 텍스트를 여러 단어로 변형하거나 여러 개의 동의어나 유의어를 활용한 검색은 불가능하다.
검색엔진은 비정형 데이터를 색인하고 검색할 수 있다.
여기서 계속 색인, 색인이야기를 반복하는데, RDBMS와 엘라스틱서치는 인덱스라는 개념이 다르다.
- 엘라스틱서치의 인덱스: 형태소를 기반으로 검색을 빠르게 만들어 주는 도구
- RDBMS의 인덱스: WHERE절의 쿼리와 JOIN을 빠르게 만드는 보조 데이터 도구
엘라스틱서치와 데이터베이스는 데이터 추가, 수정, 삭제에도 차이가 있다. 자세한 내용은 아래 표를 보도록 하자.
| 엘라스틱서치서 사용하는 HTTP 메소드 | 기능 | 데이터베이스 질의 문법 |
| GET | 데이터 조회 | SELECT |
| PUT | 데이터 생성 | INSERT |
| POST | 인덱스 업데이트, 데이터 조회 | UPDATE, SELECT |
| DELETE | 데이터 삭제 | DELETE |
| HEAD | 인덱스 정보 확인 | - |
우선 엘라스틱서치는 기본적으로 HTTP를 통해 JSON 형식의 RESTful API를 이용한다.
여기서 RESTful API는 HTTP 헤더와 URL만 사용하여 다양한 형태의 요청을 할 수 있는 HTTP 프로토콜을 최대한 활용하도록 고안된 아키텍처다.
다음은 엘라스틱서치를 사용하기 위한 간단한 API 요청 구조다.
curl -X(method) http://host:port/(index)/(type)/(document_id) -d '{json 데이터}'
위 구조의 해석은 아래와 같다.
- curl : 리눅스 기본 명령어로, 이를 이용해 터미널의 커맨드 라인에서 간단히 http 요청을 보낼 수 있음
- -X: curl에서 제공하는 -X 옵션으로, GET_POST_PUT_DELETE_HEAD 같은 HTTP 메서드를 설정 가능
만약에 아래와 같은 DB가 있다고 가정해보자
| ID | Name | Location | Gender | Date |
| 1 | 가마돈 | 서울 | 남 | 2022-11-08 |
SQL문으로 이름을 검색하려면,
SELECT * FROM USER WHERE Name like '%가마돈%'
으로 검색해야한다.
엘라스틱서치에서는
GET http://localhost:9200/user/_search?q=Name:가마돈
이러한 Search API를 사용해야 한다. 참고로 엘라스틱으로 검색하면 JSON 문서 형태로 출력된다.
지금은 한국어니까 상관 없지만 영어라면, SQL문에서 '대소문자 구분'이나 '1글자 오타'에 대해서 대처하기 어렵다.
엘라스틱서치는 더 유연하다. 역색인되는 문자열 전체를 정책에 따라 소문자 혹은 대문자로 생성, 쿼리가 들어오는 필터를 색인 시간과 검색 시간에 동일히 지정하면 해당하는 쿼리에 어떤 문자열을 넣어도 검색이 가능하다.
...여기까지가 '엘라스틱서치'의 기본이고
이 다음은 '엘라스틱 서치가 최고인 이유'이다. 핵심만 요약해봤다.
- 오픈소스 검색엔진: 아파치 재단의 루씬(Lucene)기반으로 많이 사용됨
- 전문 검색: 좀 더 고차원적인 전문 검색(Full Text, 내용 전체를 색인해 특정 단어가 포함된 문서를 검색하는 것)
- 통계 분석: 키바나로 통계 분석, 로그 시각화 및 분석 가능
- 스키마리스(Schemaless): 스키마 없음 -> 정형화되지 않은 형태도 색인 및 검색 가능
- RESTful API: 다양한 플랫폼에서 이용 가능
- 멀티테넌시(Multi-tenancy): 서로 상이한 인덱스라도 검색할 필드명만 같으면, 여러 인덱스를 한번에 조회 가능
- Document-Oriented: 계층 구조라 좋다
- 역색인(Inverted-Index) : 해당 단어만 찾으면 단어가 포함된 모든 문서의 위치를 알 수 있어 빠르게 찾을 수 있다.
- 확장성과 가용성: 대량의 문서를 효율적으로 처리가능
약점에 대한 내용도 있는데, Near-Realtime, Non-Rollback-Transaction, 데이터 업데이트 제공 안함이 있다. 장점만 알고있으면 될 것 같다.
실습 환경 구축
일단 오라클 페이지에서 JDK 설치해 자바 런타임을 사용할 수 있도록 하고(본인은 jdk1.8.0_201 사용),
엘라스틱서치 페이지에서 '6.4.3' 버전을 다운받았다.
(지금 기준으로 8.5.0이 최신 버전인데, 책이 6.4.3 기반으로 진행되서 그럼)
https://www.elastic.co/kr/downloads/past-releases/elasticsearch-6-4-3
Elasticsearch 6.4.3
www.elastic.co
윈도우 환경이라서 Windows 버전 설치한 후, 해제해서
cmd 실행 -> 압축 푼 폴더의 bin 폴더로 이동 -> elasticsearch.bat로 엘라스틱서치 실행
순으로 진행했다.
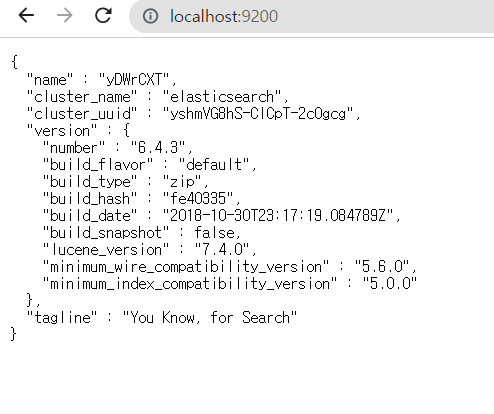
그러면 아래 그림처럼 주소가 뜨는데,

여기를 들어가면 아래처럼 엘라스틱서치의 클러스터 이름과 버전 정보가 나타난다.
이제 여기서 원활한 실습을 위해서 config/elasticsearch.yml 파일을 수정해야 한다고 한다.

여기서 cluster.name, node.name, path.data, path.logs, path.repo, network.host, http.port, transport.tcp.port, node.master, node.data를 수정해야 한다고 한다.
cluster.name: javacafe-cluster
node.name: javacafe-node1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
path.repo:(리눅스 기준) ['/es/book_backup/search_example", "/es/book_backup/agg_example"]
(윈도우 기준) ["C:\\es\\book_backup\\search_example", "C:\\es\\book_backup\\agg_example"]여기서 각 키워드에 대한 해석은 아래와 같다.
cluster.name: 클러스터로 여러 노드를 하나로 묶을 수 있는데, 클러스터의 이름을 지정
node.name: 노드의 이름
path.data: 엘라스틱서치의 '인덱스 경로'를 지정한다. 설정하지 않으면
기본적으로 엘라스틱서치 하위의 data 디렉토리에 인덱스 생성됨
path.logs: 로그를 저장할 경로. default값은 /path/to/logs
----------------------------------------------------------------------------
path.repo: 엘라스틱서치 인덱스를 백업하기 위한 스냅숏의 경로.
윈도우 기준, C:/es/book_backup 디렉터리를 우선 생성한 다음에
path.repo: ["C:\\es\\book_backup\\search_example", "C:\\es\\book_backup\\agg_example"]을 적용해야 한다.
----------------------------------------------------------------------------
network.host: 특정 IP만 엘라스틱서치에 접근하도록 허용 가능. 0.0.0.0은 모든 아이피를 허용한다는 뜻
http.port: HTTP API 호출을 위한 포트번호 지정. 기본값은 9200
transport.tcp.port: 엘라스틱서치 클라이언트가 접근할 수 있는 TCP 포트. 기본값 9300
----------------------------------------------------------------------------
node.master: 마스터 노드로 동작 여부.
node.data: 데이터 노드로 동작 여부.
위 둘 다 true로 하면 마스터 노드와 데이터 노드의 역할을 함께 수행 가능이렇게 설정한 다음에 엘라스틱서치를 다시 실행한다.

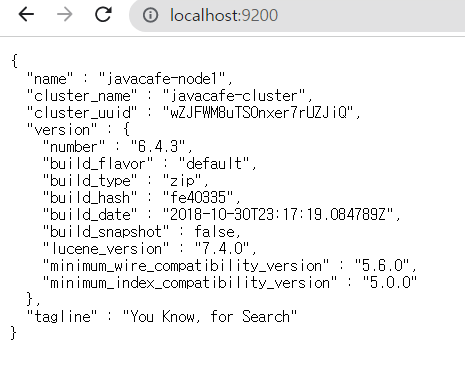
이제 path.repo에서 설정한 물리적인 스냅숏 데이터를 엘라스틱서치로 인식시켜야 한다..는데 스냅숏?
스냅숏에 대해 짧게 짚고 넘어가자.
스냅숏(Snapshot): 특정 시간에 데이터 저장 장치의 상태를별도의 파일이나 이미지로 저장하는 기술
뭐 그렇다고 한다.
아래 명령어를 입력해서 search_example 데이터가 javacafe라는 이름의 논리적인 스냅숏으로 생성되게 한다고 한다.
curl -XPUT 'http://localhost:9200/_snapshot/javacafe' -d '{"type" : "fs", "settings" : {"location" : "/es/book_backup/search_example", "compress":true}}'
근데 계속 아래와 같은 에러가 나왔다.
curl: (3) URL using bad/illegal format or missing URL
curl: (3) URL using bad/illegal format or missing URL
curl: (6) Could not resolve host: fs,
curl: (6) Could not resolve host: settings
curl: (3) URL using bad/illegal format or missing URL
curl: (3) unmatched brace in URL position 1:
{location
Windows용 curl을 설치해도, cmder를 이용해도, "/es/book_backup/search_example"를 "C:\\es\\book_backup\\search_example"로 수정해도 해결이 안된다...
우선 여기 체크해두고, 키바나 설치로 넘어가기로 했다. 찜찜하다
키바나
엘라스틱에서 제공하는 데이터 시각화 프로그램으로, 색인된 데이터를 검색하거나 문서를 추가-삭제하는 등의 기능을 손쉽게 구현할 수 있다.
키바나 페이지에서 알맞는 파일 다운받고
https://www.elastic.co/kr/downloads/kibana
Download Kibana Free | Get Started Now
Download Kibana or the complete Elastic Stack (formerly ELK stack) for free and start visualizing, analyzing, and exploring your data with Elastic in minutes.
www.elastic.co
config 디렉토리 열어서 kibana.yml에 다음 내용을 추가하거나 주석을 해제한다.
elasticsearch.url: "http://localhost:9200"
그리고 kibana.bat 파일을 실행한 뒤 localhost:5601에 접속했다.

... 책에서 이야기한 대로 딱딱 되기를 바랬는데, 윈도우에서는 참 뭐가 잘 안된다...
엘라스틱을 제대로 실행할 수 있는 다른 방법을 따로 알아봐야겠다.
'ElasticSearch' 카테고리의 다른 글
| 엘라스틱서치 오타 교정, 자동 완성 등 구현 (0) | 2022.11.14 |
|---|---|
| 엘라스틱서치, 검색 (0) | 2022.11.10 |
| 인덱스 템플릿과 분석기 (0) | 2022.11.09 |
| 엘라스틱서치 기본 (0) | 2022.11.09 |
| 엘라스틱 설치 다시시도 (0) | 2022.11.09 |