
엘라스틱서치의 기본기를 다져보자.
1. 준비 작업
우선 cmd에서 elasticsearch와 kibana를 실행, 키바나의 Dev Tools에 있는 콘솔을 이용해 REST API를 호출하도록 하자.
REST API(Representational State Transfer API) : 웹(HTTP)의 장점을 이용해 릿소스를 주고받는 형태이며, 메소드(method)와 경로(URL)가 합쳐진 형태다.
메소드는 POST, GET, PUT, DELETE가 있다. CRUD(Create, Read, Update, Delete)를 이걸로 수행한다.
이제 키바나에 들어가서 왼쪽 상단의 토글 메뉴를 클릭, Management -> Dev Tools를 선택한다.


이 키바나 콘솔을 이용하면, 복잡한 앱 개발이나 프로그램 설치 없이 엘라스틱서치와 REST API로 통신할 수 있다.
왼쪽 입력창에 REST API를 입력해 세모모양(▷) 실행 버튼을 누르면 HTTP 요청문을 보내준다. 또 문법 검사도 해준다!
2. 시스템 상태 확인
엘라스틱서치의 현재 상태를 빠르게 확인할 수 있는 방법으로 cat API를 사용.
cat는 compact and aligned text의 약어로 콘솔에서 시스템 상태를 확인할 때 가독성을 높일 목적으로 만든 API다.
일반적으로 cat API를 통해 제공하는 기능들은 시스템의 상태를 확인하는 용도로 많이 사용된다.
우리도 한번 사용해보자.
GET _cat을 요청해 cat API가 지원하는 목록들을 확인해보자.

cat API를 통해 노드, 샤드, 템플릿 등의 상태 정보나 통계 정보를 확인할 수 있다.
GET _cat/indices?v를 요청해 클러스터 내부 인덱스 목록을 확인해보자.

여기서 '?' 뒤에는 몇 가지 파라미터가 붙는데, 'v' 파라미터를 사용하면 컬럼의 이름을 확인할 수 있다.
다른 파라미터들 중 s는 정렬(sort), h는 헤더(header)를 의미한다.
cat API를 사용ㅇ하면 터미널 환경에서 엔딕슬을 빠르고 간단하게 상태 점검을 할 수 있다. 윈도우 명령 프롬프트(cmd)에서 curl -X GET "localhost:9200/_cat/indices?v"를 실행하면 키바나 콘솔에서 얻은 것과 같은 결과를 얻을 수 있다.

퀴즈! 인덱스 외에 Nodes, Shards 등도 호출해보자.
간단하다. /_cat/nodes, /_cat/shards를 입력하면 된다.
참고로 index의 복수형이 indices다.


3. 샘플 데이터 불러오기
이제 검색을 해볼건데, 실습 데이터가 없으면 실습을 할 수 없다!
다행이도, 엘라스틱 스택은 3가지 샘플 데이터를 기본으로 제공한다.
키바나의 홈 화면 우측 하단에 Try out sample data가 있다. 여기로 들어가보자.

그러면 아래처럼 sample data를 추가할 수 있는 페이지가 나오는데, 다 추가해주자

4. 인덱스와 도큐먼트
간략하게 짚자면,
- 인덱스: 도큐먼트를 저장하는 논리적 구분자
- 도큐먼트: 실제 데이터를 저장하는 단위
- 필드: 데이터 묶음
(뭉탱이)
도큐먼트를 엘라스틱서치 인덱스에 저장하고, 읽고, 수정하고, 삭제하는 CRUD 동작을 수행하여보자.
우선, 인덱스를 하나 생성해보자. 인덱스 생성을 요청하는 API는 아래와 같다.

이렇게 만든 인덱스는 GET으로 확인할 수 있다.

이제 삭제해보자. 삭제는? DELETE다.

너무 확 지나가서 하나만 짚고 넘어가자면, index1을 생성하고 /_cat/indices를 수행해보면 아래와 같이 나온다.

DELETE index1하면 저거 사라진다. 끝!
이제, 도큐먼트를 생성해보자.
도큐먼트는 반드시 하나의 인덱스에 포함되어야 한다고 한다. 엘라스틱서치에서 도큐먼트를 인덱스에 포함시키는 것을 인덱싱(indexing)이라 하는데, 한번 해보자.
PUT index2/_doc/1
{
"name": "mike",
"age": 25,
"gender": "male"
}
존재하지 않았던 index2를 생성하면서 동시에 index2 인덱스에 도큐먼트를 인덱싱한다.
index2는 인덱스 이름, _doc은 엔드포인트 구분을 위한 예약어(일단 이렇게 알고 넘어가자), 숫자 1은 인덱싱할 도큐먼트의 '고유 아이디'다.
도큐먼트에는 age, gender, name이라는 필드가 있고, 각 필드에는 값이 있다.
index2 인덱스가 정상적으로 생성되었는지 키바나 콘솔에서 index2 인덱스를 확인해보자.

age는 long, gender-name은 text 타입으로 필드가 지정되었다.
우리가 데이터 타입을 지정하지 않아도 알아서 엘라스틱서치가 지정해주는데, 이를 다이나믹 매핑(dynamic mapping)이라 한다.
여기에, country라는 이름의 새로운 필드가 추가된 도큐먼트를 인덱싱해보자.

뭐... 잘 인덱싱 되었다. 필드 추가는 문제가 되지 않는다는 건가...
그러면 이제 데이터 타입이 잘못된 도큐먼트 인덱싱을 시도해보자.
age에 "20"라는 text를 넣어보자!

관계형 데이터베이스라면 오류가 발생했겠지만, 스키마에 유연하게 대응하는 엘라스틱서치는 타입을 변환해 저장한다. 즉, 이렇게 해도 문제가 없다는 뜻.
그러면, 아예 age에 텍스트를 넣어보면 어떻게 될까?

역시 이건 엘라스틱서치라도 안된다.
이제 도큐먼트를 읽어보자. 도큐먼트를 읽는 방법은 크게 두 개다.
- 도큐먼트 아이디를 이용해 조회
- 쿼리 DSL(Domain Specific Language)라는 쿼리문을 이용해 검색
참고로 저 DSL은 엘라스틱 서치가 제공하는 것이다.
우선, 1번 방식으로 조회해보자.

이제 2번 방식으로 조회해보자.

아, _search DSL 쿼리를 사용하면 index2 인덱스 내의 모든 도큐먼트를 가져온다. DSL 쿼리는 나중에 다룬다고 함 ㅇㅇ.
이제 수정해보자.
수정은 (읽기 + 입력) 형태이다.
아래의 예시를 보면 된다.

1번 도큐먼트의 name, age 필드 값을 변경하는 API다. 사실, 도큐먼트를 인덱싱하는 과정에서 같은 도큐먼트 아이디가 있으면 덮어쓰기 되는 것이다.
_update라는 엔드포인트(endpoint)를 추가해 특정 필드의 값만 업데이트할 수 있...지만
엘라스틱서치에서 '수정'을 하는 것은 매우 비효율적이다. 수정 작업 할거면 다른 DB 이용하는 게 좋다고 한다.
마지막은 도큐먼트 삭제다.
이거도 앞을 DELETE로만 바꾸면 된다.

도큐먼트 삭제는 수정만큼은 아니지만, 비용이 많이 들어가므로 사용 시에 주의해야 한다.
이 다음으로는 응답 메시지에 대한 내용이 나오는데, 상태 코드는 그때마다 검색하면 되니 정리만 해두자.
| 코드 | 상태 | 해결방법 |
| 200, 201 | 정상 | |
| 4xx | 클라이언트 오류 | 클라이언트에서 문제점 수정 |
| 404 | 요청한 리소스 없음 | 인덱스나 도큐먼트가 존재하는지 체크 |
| 405 | 요청 메소드를 지원하지 않음 | API 사용법 다시 확인 |
| 429 | 요청 과부화 | 재전송 or 노드 추가 같은 조치 |
| 5xx | 서버 오류 | 엘라스틱서치 로그 확인 후 조치 |
사실 상태 코드 뿐 아니라, 에러 메시지도 확인할 수 있으니 그때마다 알아서 구글링해서 해결할 문제인듯 하다.
5. 벌크 데이터
벌크데이터가 뭔지 잘 몰랐는데, 쉽게 이야기해서 한 번에 여러 데이터를 의미하는 듯 하다.
(벌크 bulk를 번역하면 무더기라고 한다. 무더기뭉탱이무더기)
여기서의 요점은, '20개의 도큐먼트에 대해 API를 20번 호출하지 말고, 1번 호출해 인덱싱하면 더 빠르고 경제적이다'라는 점이다.
bulk API라는 걸 지원하는데, 아래와 같이 쓰인다.

bulk API는 '읽기'는 지원하지 않고, 생성/수정/삭제만 지원한다.
벌크 데이터 포맷을 보면 삭제(delete)만 한 줄로 작성하고 나머지 작업들은 두줄로 작성된다.
각 줄 사이에는 쉼표 등 별도의 구분자가 없고 라인 사이 공백을 허용하지 않는...다는데
솔직히 이렇게 쓰면 한번에 알 수가 없다.
아래는 앞서 만든 index2 인덱스에 2개의 도큐먼트를 벌크 형태로 생성하는 코드다.

현업에서는 벌크 데이터를 파일로 만들어서 사용한다고도 한다.
한번 해보고 넘어가자.
1. C 드라이브 밑에 example 폴더 생성

2. cmd에서 방금 생성한 example로 이동. 여기서 "copy con bulk_index2" 명령을 치면 bulk_index2 파일이 만들어진다.
{"index": {"_index": "index2", "_id": "6"}}
{"name": "hong", "age": 10, "gender": "female"}
{"index": {"_index": "index2", "_id": "7"}}
{"name": "choi", "age": 15, "gender": "male}
이렇게 입력하고 Ctrl + C 버튼을 누르면 파일이 생성된다. (메모장 이용해서 파일 만들어도 된다고 한다.)

이렇게 해서 curl을 이용해 REST API로 보내면 된다고 한다.
curl -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/_bulk --data-binary @./bulk_index2

위 코드에 대한 해석은 아래와 같다.
- -H : curl의 헤더 옵션으로, NDJSON 타입의 콘텐츠를 사용한다는 의미
- -X : 요청 메소드를 기술
- localhost:9200: 엘라스틱서치가 동작하는 호스트 주소
- /_bulk: bulk API를 호출
- --data-binary: POST 메소드에 우리가 만든 파일(bulk_index2)을 바이너리 형태로 전송
6. 매핑
관계형 데이터베이스에 '스키마'가 있다면, 엘라스틱서치에서는 '매핑'이 있다.
엘라스틱 서치가 자동으로 하면 '다이나믹 매핑'이고, 사용자가 직접 설정하면 '명시적 매핑'이다.
그냥 엘라스틱서치한테 다 맡기면 안되나..?라는 생각을 했는데, 문자열이 텍스트(text)와 키워드(keyword) 타입으로 나뉜다고 하니 정리해야겠다는 생각이 들었다.
다이나믹 매핑은 아래의 기준을 기반으로 진행된다.
| 원본 소스 데이터 타입 | 다이내믹 매핑으로 변환된 데이터 타입 |
| null | 필드 추가 안함 |
| boolean | boolean |
| float | float |
| integer | long |
| object | object |
| string | date, text, keyword |
다이나믹 매핑은 편하다는 장점이 있지만, 아래의 문제가 있다.
- 숫자 타입은 무조건 범위가 가장 넓은 long으로 매핑되어 불필요한 메모리 차지
- 문자열의 경우 검색과 정렬 등을 고려한 매핑이 제대로 되지 않음
그러면 한번, index2의 매핑 상태를 확인해보자.
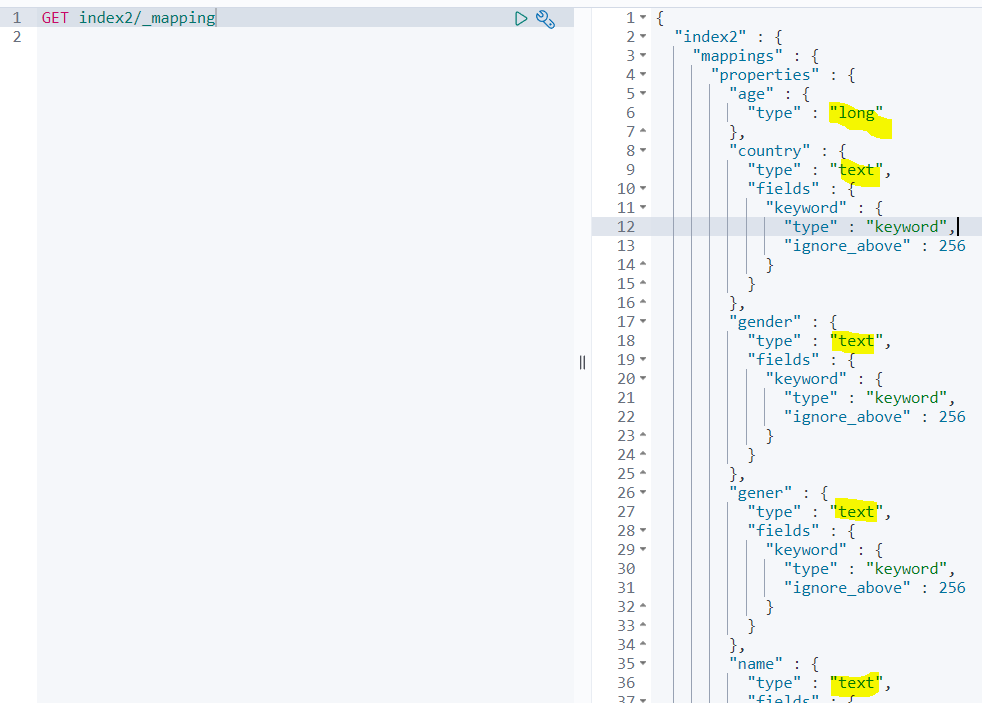
long, text 원툴이다.
나이의 경우 수십억을 표현하는 long 타입보다는 short 타입이 유리하고,
country나 gender 같은 범주형 데이터는 전문 검색보다는 일반적으로 집계나 정렬, 필터링을 위해서 keyword 타입으로 지정하는 게 좋다.
이제, 사용자가 직접 매핑하는 방법을 보도록 하자.

이런~식으로 매핑하면 된다.
이렇게만 마무리하면... 근데 뭐가 좋음?이라는 결론에 다다르게 된다.
이런건 한번 정의해두었다가, 나중에 매핑할때 찾아보는게 장땡이다!
| 데이터 형태 | 데이터 타입 | 설명 |
| 텍스트 | text | 전문 검색이 필요한 데이터, 텍스트 분석기가 텍스트를 적은 단위로 분리 |
| keyword | 정렬이나 집계에 사용되는 데이터, 원문을 통째로 인덱싱 | |
| 날짜 | date | 날짜 및 시간 데이터 |
| 정수 | byte | 부호 있는 8비트 데이터 |
| short | 부호 있는 16비트 데이터 | |
| integer | 부호 있는 32비트 데이터 | |
| long | 부호 있는 64비트 데이터 | |
| 실수 | scaled_float | float 데이터에 특정 값을 곱해 정수형으로 바꿈. 정확도는 떨어지나 특정 상황에서 애용 |
| half_float | 16비트 부동소수점 실수 데이터 | |
| double | 32비트 부동소수점 실수 데이터 | |
| float | 64비트 부동소수점 실수 데이터 | |
| 불린 | boolean | 참 / 거짓 |
| IP 주소 | ip | ipv4, ipv6 타입 ip 주소 입력 |
| 위치 정보 | geo-point | 위도, 경도 값을 가짐 |
| geo-shape | 하나의 위치 포인트가 아닌 임의의 지형 | |
| 범위 값 | integer_range | 정수형 범위, 최솟값과 최댓값을 통해 범위를 입력 |
| long_range | 정수형 범위 | |
| float_range | 실수형 범위 | |
| double_range | 실수형 범위 | |
| ip_range | IP 주소 범위 | |
| date_range | 날짜/시간 데이터 범위 | |
| 객체형 | object | 계층 구조를 가지는 형태로, 필드 안에 다른 필드들이 들어갈 수 있음 |
| 배열형 | nested | 배열형 객체 저장. 배열 내부의 객체에 쿼리로 접근 가능 |
| join | 부모/자식 관계 표현 가능 |
7. 멀티 필드를 활용한 문자열 처리
마지막으로, 멀티 필드를 사용해 두 타입을 동시에 활용해보자.
우선, 다음 문장은 텍스트 타입으로 지정하는 것이 좋다.
"We offer solutions for enterprise search, observability, and security that are built on a single, flexible technology stack that can be deployed anywhere."
텍스트 타입으로 지정된 문자열은 분석기(analyzer)에 의해 토큰(token)으로 분리되고, 이렇게 분리된 토큰들은 인덱싱되는데 이를 역-인덱싱(inverted-indexing)이라고 한다.
이때, 역-인덱스에 저장된 토큰들을 용어(term)라고 한다.
우선 엘라스틱서치에서 제공하는 기능을 이용해서 텍스트가 어떻게 용어 단위로 분석되는지 확인해보자.

텍스트가 여러 token으로 분리되고, 불필요한 토큰은 걸러내고 대소문자를 통일하는 등 가공 과정을 거쳐 용어가 된다.
이제, 텍스트 타입을 가진 text_index 인덱스를 생성해보자

text_index라는 이름의 인덱스를 생성, contents 필드의 타입을 텍스트 타입으로 매핑하자.
그리고, 도큐먼트 하나를 인덱싱해보자.
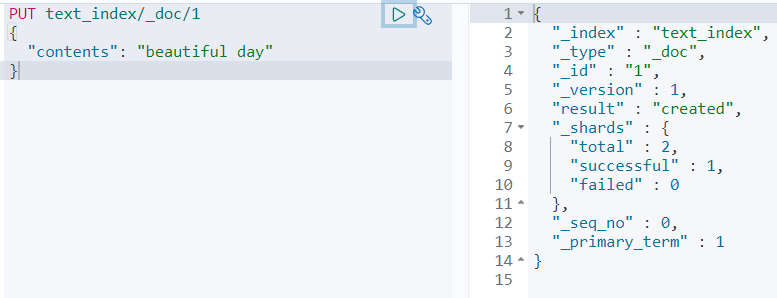
타입이 텍스트이기 때문에, 분석기에 의해서 beautiful과 day라는 용어 단위로 분리되 역인덱스에 저장된다.
이제 dsl 쿼리로 검색해보자.

DSL 쿼리문에서 match는 전문 검색을 할 수 있는 쿼리며, contents 필드에 있는 역인덱싱된 용어 중 일치하는 용어가 있는 도큐먼트를 찾는 쿼리문이다. 현재 1번 도큐먼트의 contents 필드에 day라는 용어가 있어 검색이 된 것이다.
반대로 키워드 타입이면? day로는 검색이 안될 것이다.
아래는 그것을 실행한 화면이다.


근데 뭔가 이상하다.
이거 주제가 '멀티 필드' 아니었나?
이제 멀티 필드에 대해 이야기해보자.
멀티 필드는 단일 필드 입력에 대해 여러 하위 필드를 정의하는 기능으로, 이를 위해 field라는 매핑 파라미터가 사용된다. fields는 하나의 필드를 여러 용도로 사용할 수 있게 만들어준다.
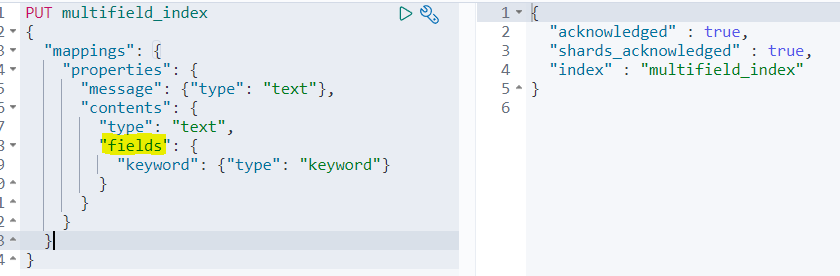
messge, contents라는 2개의 필드를 가진 multifield_index 인덱스를 생성한 뒤, contents 필드에 '멀티 필드'를 정의했다.
이제 도큐먼트를 인덱싱해보자.

다음 쿼리를 수행해보자.

contents는 텍스트 타입으로 매핑되어있기 때문에, 3개 다 검색된다.
다음 쿼리를 수행해보자

contents 뒤에 keyword를 추가해 하위 필드를 참조할 수 있다. 여기서 keyword는 키워드 타입이기 때문에 검색이 안된다.
다음 쿼리를 수행해보자.

aggs는 집계를 하기 위한 쿼리이다.
contents.keyword 값이 같은 도큐먼트끼리 그룹핑이 된다. beautiful day라는 도큐먼트 2개, wonderful day라는 도큐먼트 1개가 그룹핑된다.
참고로 저기에 contents.keyword 말고 contents를 넣으면 에러가 발생한다.

illegal_argument_exception에러에서 '텍스트 필드는 집계에 알맞지 못함'이라는 언급이 있다.
집계 함수에 대한 내용을 학습하면 이해할 수 있을 것 같다.
일단... 이렇게 해서 기본적인 내용을 다루어보았다.
기본만 나갔는데도 양이 너무 많다;
다음에는 인덱스 템플릿, 분석기를 다뤄볼 예정이다.
'ElasticSearch' 카테고리의 다른 글
| 엘라스틱서치 오타 교정, 자동 완성 등 구현 (0) | 2022.11.14 |
|---|---|
| 엘라스틱서치, 검색 (0) | 2022.11.10 |
| 인덱스 템플릿과 분석기 (0) | 2022.11.09 |
| 엘라스틱 설치 다시시도 (0) | 2022.11.09 |
| 검색 시스템과 ElasticSearch (0) | 2022.11.08 |