
드디어 엘라스틱서치로 검색을 해본다.
일단, 책에서는 엘라스틱서치의 검색에 대해 아래와 같이 설명한다.
엘라트식서치는 텍스트, 숫자, 정형, 비정형 데이터를 저장한 다음에 인덱싱을 마치고 나면 바로 쿼리를 실행해 결과를 얻을 수 있다.
특히, 단순 텍스트 매칭 기법을 넘어서 텍스트를 여러 단어로 변형해 검색할 수 있으며, 스코어링 알고리즘을 적용해 연관성이 높은 결과에 대한 제어가 가능하므로 대량의 데이터를 대상으로 빠르고 정확한 검색이 가능하게 만들어준다.
이번 실습으로 쿼리 컨텍스트와 필터 컨텍스트의 차이, 쿼리 스트링과 쿼리 DSL의 차이, 스코어 계산 알고리즘, 자주 사용하는 쿼리를 본격적으로 배우게 된다.
1. 쿼리 컨텍스트와 필터 컨텍스트
일단 두 컨텍스트의 이론은 다음과 같다.
- 쿼리 컨텍스트: 질의에 대한 유사도를 계산하여 이를 기준으로 더 정확한 결과를 먼저 보여줌
- 필터 컨텍스트: 유사도를 계산하지 않고 일치 여부에 따른 결과만을 반환
예를 들어, 도큐먼트에서 '엘라스틱'이라는 단어가 포함되어 있는지 찾을 때는 쿼리 컨텍스트를 이용하는데, 연관성을 계산하여 최대한 비슷한 도큐먼트들을 찾아준다.
반면, 도큐먼트 제목이 정확하게 '엘라스틱'인 문서를 찾기 위해서는 필터 컨텍스트를 사용한다. 예/아니오 결과만 확인하면 되니까.
이런 점 때문에 필터 컨텍스트는 스코어 계산 과정이 없으며, 캐시를 이용할 수 있다.
한번 쿼리 컨텍스트를 실행해보자.
(kibana_sample_data_ecommerce는 키바나에서 제공하는 연습용 데이터)
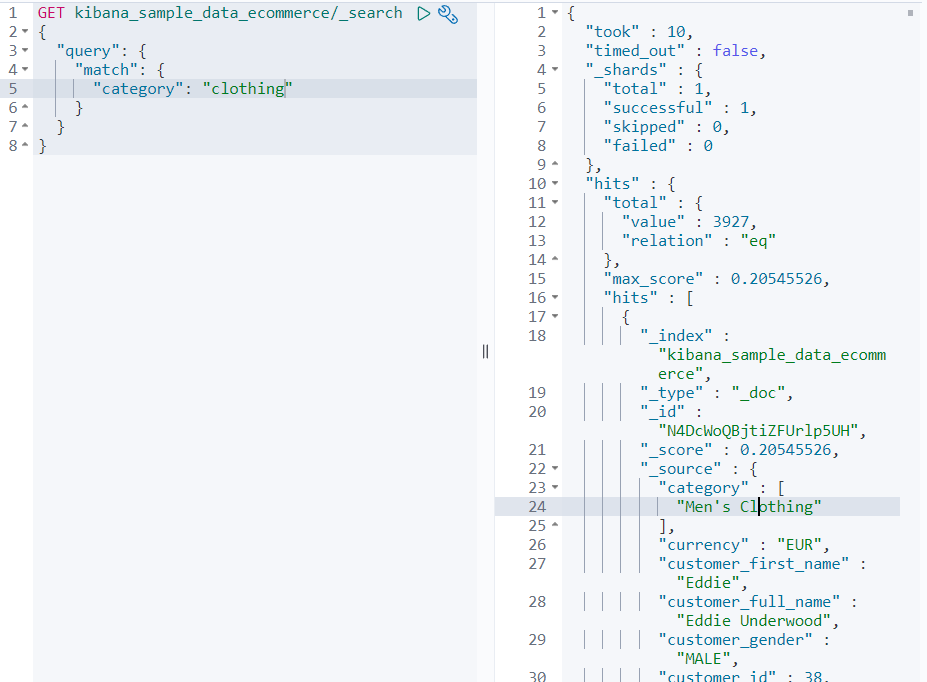
실행 결과, 'Men's Clothing'이라는 카테고리를 찾아냈다.
위 그림에서 hits.total(11 line)이 3927이라고 쓰여있는데, 이만큼의 도큐먼트를 찾았음을 의미한다.
쿼리 컨텍스트는 유사도 계산 알고리즘에 의해 가장 연관성 높은 도큐먼트 순으로 정렬한다.
21번째 줄에 '_score'라고 있는데, 이는 유사도를 나타내는 지표이다.
그러면 이제, 필터 컨텍스트를 실행해보자

필터는 참-거짓으로 출력하므로 논리(bool) 쿼리 내부에 넣는다.
이때, _score : 0.0인걸 볼 수 있는데, 유사도를 계산하지 않는다는 의미이다.
2. 쿼리 스트링과 쿼리 DSL
- 쿼리 스트링(Query String): 한 줄 정도의 간단한 쿼리에 사용
- 쿼리 DSL(Query Domain Specific Language): 엘라스틱에서 제공하는 쿼리 전용 언어로, JSON 기반이다. 주로 복잡한 논리 조건이나 코드 수준에서 쿼리를 제어할 때 사용
한번 쿼리 스트링을 실행해보자.
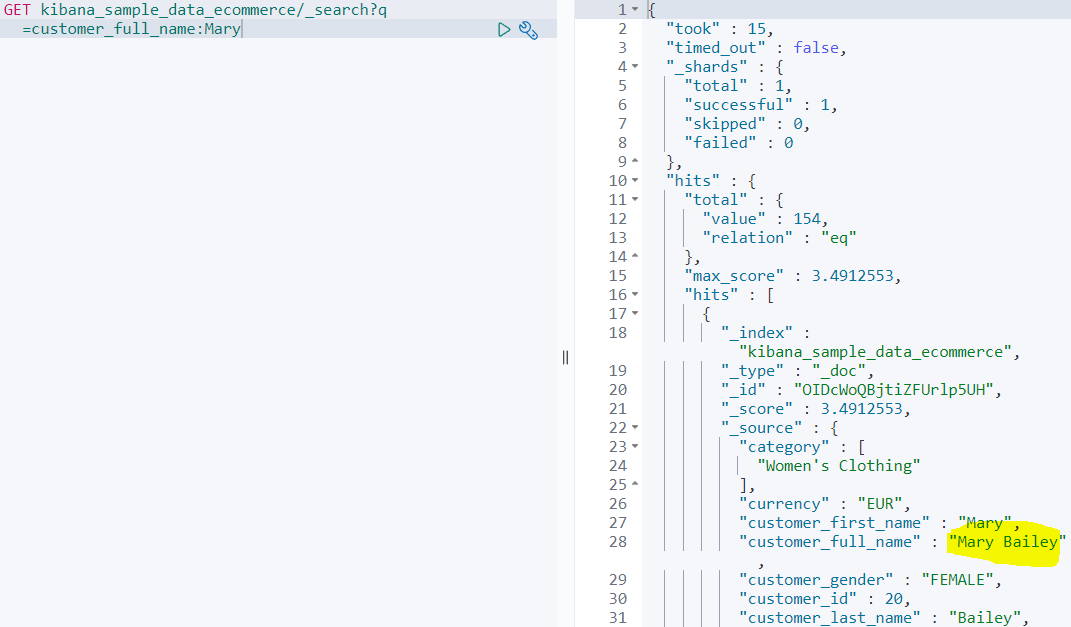
쿼리 스트링의 내용은 간단하다. customer_full_name에 Mary가 들어가는 도큐먼트를 다 찾으라는 의미다.
쿼리 DSL로 바꾸면 다음과 같다.
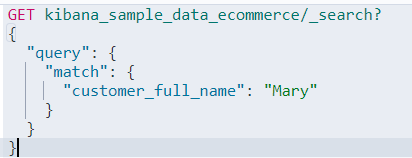
3. 유사도 스코어
쿼리 컨텍스트는 엘라스틱에서 지원하는 다양한 스코어 알고리즘을 사용하는데, 기본적으로 BM25 알고리즘을 이용해 유사도 스코어를 계산한다.
그러면, 쿼리를 요청해보고 스코어가 어떤 식으로 계산되는지 알아보자.
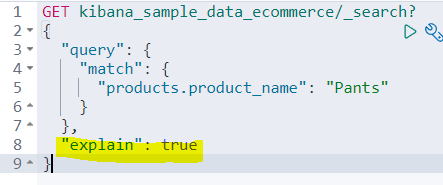
explain: true를 추가하면, 쿼리 내부적인 최적화 방법과 어떤 경로를 통해 검색되었으며 어떤 기준으로 스코어가 계산되었는지 알 수 있다.
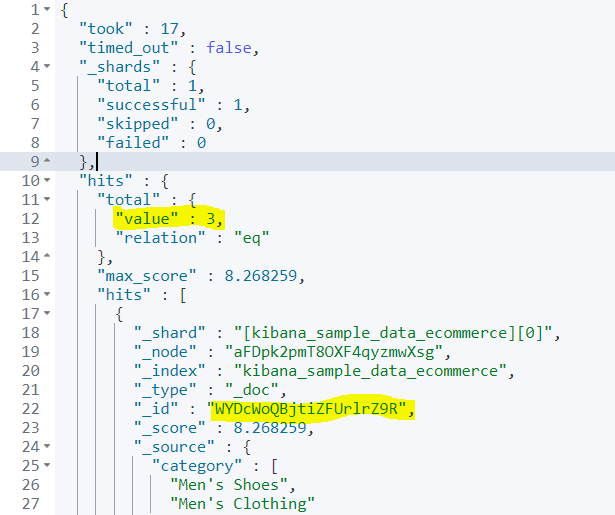
총 3개의 도큐먼트를 찾았는데, 그 중 스코어가 가장 높은 id가 저 WY...뭐시기다.

product_name에 Pants가 있는 것을 볼 수 있고

스코어 계산식은 description 항목과 details 항목에 제공된다.
4. 스코어 알고리즘 BM25 이해하기
일단, 위 details를 이해하기 위해서는 스코어 알고리즘인 bm25에 대한 이해가 필요하다.
우선 쿼리 컨텍스트로 요청한 응답값을 보면 히트된 도큐먼트는 모두 스코어 값을 가지고 있다.
엘라스틱서치는 5버전 이전에는 tf-idf 알고리즘을 사용했지만, 이젠 bm25를 사용하게 되었다.
BM25는 TF(Term Frequency), IDF(Inverse Document Frequency) 개념에다가 문서 길이를 고려한 알고리즘이다.
검색어가 문서에서 얼마나 자주 나타나는지, 검색어가 문서 내에서 얼마나 중요한 용어인지 등을 판단하는 근거를 제공한다.
일단, TF와 IDF가 뭔지 하나하나 짚어보자.
IDF 계산
문서 빈도는 특정 용어가 얼마나 자주 등장했는지를 의미하는 지표이다.
문서 빈도가 왜 중요한가? 바로 '자주 등장하는 용어는 중요하지 않을 확률이 높다'는 점에 있다. 주로 관사같은 경우 자주 나타나는데, 이런 흔한 용어는 실제 큰 의미가 없다.
즉, 빈도가 적을수록 가중치를 높게 주는, 문서 빈도의 역수(Inverse Document Frequency: IDF)의 개념이다.
IDF를 계산하는 식은 description에서 잘 알려주고 있다.
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",

n은 검색했던 용어가 몇 개의 도큐먼트에 있는지 알려주는 값이다.
총 3개의 도큐먼트에서 Pants라는 용어를 포함하고 있었다.
N은 총 도큐먼트 수다. kibana_sample_data_ecommerce 인덱스는 총 4657개의 도큐먼트를 가지고 있다.
TF 계산
용어 빈도는 특정 용어가 하나의 도큐먼트에 얼마나 많이 등장했는지 의미하는 지표다.
일반적으로 특정 용어가 하나의 도큐먼트에서 많이 반복되었다면 그 용어는 도큐먼트의 주제와 연관되어 있을 확률이 높다.
TF를 계산하는 식 역시 description에서 잘 알려주고 있다.
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
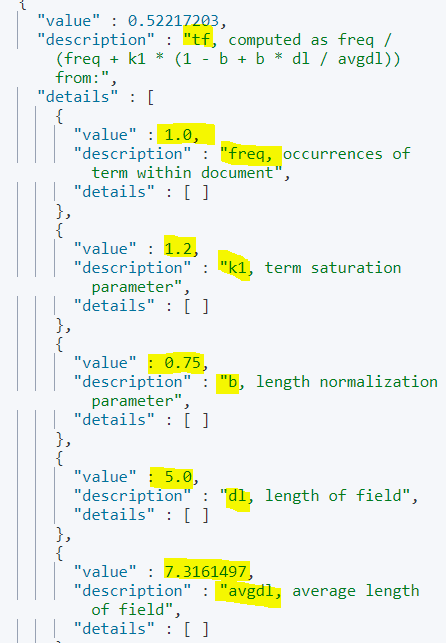
freq는 (해당) 도큐먼트 내에서 용어가 나온 횟수로, details의 첫 번째 구간이다.
k1과 b는 알고리즘을 정규화하기 위한 가중치로, 엘라스틱서치가 디폴트로 취하는 상수이다.
dl은 필드의 길이이고, avgdl은 전체 도큐먼트에서 평균 필드 길이다.
여기서 핵심은, dl이 작고 avgdl이 클수록 TF 값이 크게 나온다 = 짧은 글에서 찾고자 하는 용어가 포함될수록 가중치가 높다.
여기까지 idf, tf에 대해 알아보았는데, bm25라고 하기에는 약간 모자라다.
다음 최종 스코어 계산을 보면서 bm25를 알아보자.

최종 스코어는 idf, tf 그리고 boost 변수를 곱하면 된다. boost는 엘라스틱이 지정한 고정값으로 2.2로 고정되어 있다.
5. 쿼리
엘라스틱서치는 검색을 위해 쿼리를 지원하는데, 크게 리프 쿼리(leaf query)와 복합 쿼리(compound query)로 나뉜다.
- 리프 쿼리(Leaf Query): 특정 필드에서 용어를 찾는 쿼리로, 매치 쿼리-용어 쿼리-범위 쿼리 등이 있다.
- 복합 쿼리(Compound Query): 쿼리를 조합해 사용되는 쿼리로, 대표적으로 논리(bool) 쿼리가 있다.
리프 쿼리에는 전문 쿼리(full text query)와 용어 수준 쿼리(term level query)가 있는데, 이것에 대해 우선 알아보자.
- 전문 쿼리: 전문 검색을 하기 위해 사용되며, 인덱스 매핑 시 텍스트 타입으로 매핑해야 함
- 용어 수준 쿼리: 정확히 일치하는 용어를 찾기 위해 사용, 필드를 키워드 타입으로 매핑해야 함
강제는 아니지만 정확한 결과를 얻기 위한 권장사항이다.
우선, 전문 쿼리 동작 과정을 알아보자.

qindex 인덱스를 생성하고 contents 필드를 가지는 도큐먼트를 인덱싱한다.

그러면, contents 필드는 텍스트 타입으로 매핑한다.
텍스트 타입으로 매핑된 문자열은 분석기에 의해 '토큰'으로 분리되는데, 저 문자열이
[i, love, elastic, stack]으로 토큰화된다.
이제 전문 쿼리인 match 쿼리를 사용해 전문 검색을 해보자.
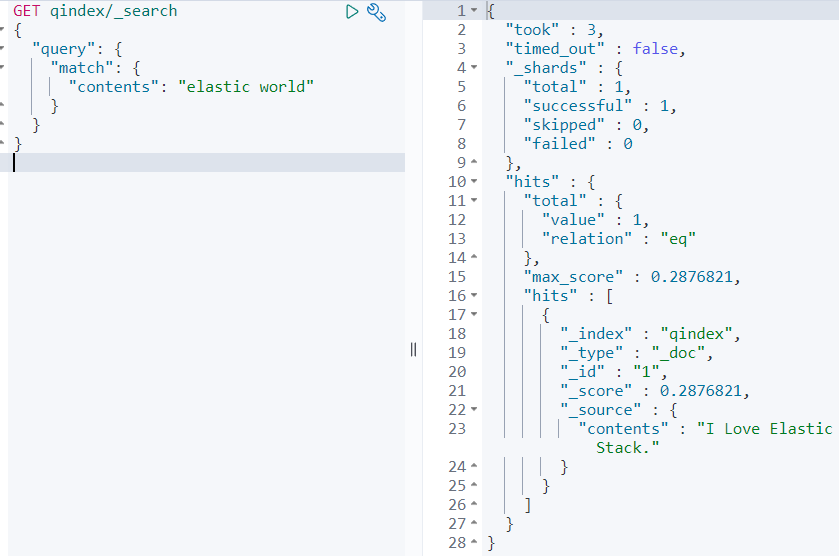
전문 쿼리를 사용하게 되면, 검색어인 'elastic world'도 분석기에 의해 토큰으로 분리되어 [elastic, world]로 토큰화된다.
즉, world가 없더라도 elastic에 의해서 저 contents가 검색되는 것이다.
전문 쿼리는 일반적으로 블로그처럼 텍스트가 많은 필드에서 특정 용어를 검색할 때 사용된다.
구글이나 네이버에서 검색어를 이용해 검색하는 방식이 전문 쿼리와 같다고 생각하면 된다고 한다.
전문 쿼리 종류로 매치 쿼리, 매치 프레이즈 쿼리, 멀티 매치 쿼리, 쿼리 스트링 쿼리 등이 있다고 하는데, 일단 듣고 넘어가자.
다음으로 용어 수준 쿼리를 알아보자,
우선, qindex 인덱스를 생성, category 필드를 가지는 도큐먼트를 인덱싱한다.

아, category 필드가 키워드 타입으로 매핑되어야 하는데, 사용자 지정 매핑으로 키워드 타입으로 설정하자.
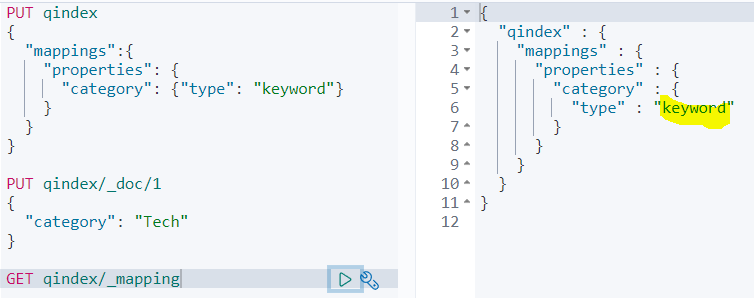
키워드 타입은 인덱싱 과정에서 분석기를 사용하지 않는다.
이 상태에서 검색을 수행해보자.
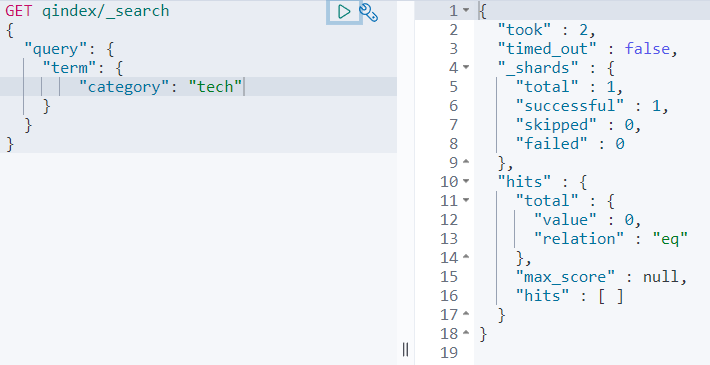
검색은 용어 쿼리를 사용하는데, 검색어 tech는 분석기를 거치지 않고 그대로 사용한다.
이렇게 분석되지 않은 검색어 tech와 분석되지 않은 도큐먼트 용어 Tech를 매칭하는데, 대소문자 차이로 매칭에 실패한다.
즉, 용어 수준 쿼리는 전문 쿼리와 다르게 정확한 용어를 검색할 때에 사용된다.
일반적으로 숫자/날짜/범주형 데이터를 정확하게 검색할 때 사용되며 관계형 데이텁데이스 WHERE 절과 비슷한 역할을 수행한다.
용어 수준 쿼리에는 용어 쿼리, 용어들 쿼리(terms query), 퍼지 쿼리(fuzzy query) 등이 있다.
이제 각 쿼리에 대해 알아보자.
매치 쿼리
매치 쿼리는 대표적인 전문 쿼리로, 전체 텍스트 중 특정 용어나 용어들을 검색할 때 사용한다.
위의 검색처럼 'elastic'과 'world'로 나눠서 둘 중 하나라도 있으면 매칭되었다고 판단한다.
저기에서 둘 다 포함되는 경우를 검색하고 싶다면, 아래와 같이 수정하면 된다.
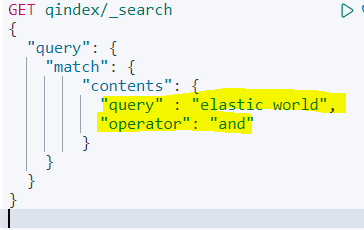
operator라는 파라미터를 정의하면 된다.
저게 왜 저렇냐면, 매치 쿼리에서 용어들 간의 공백을 OR로 처리하기 때문이다.
매치 프레이즈 쿼리
매치 쿼리와 마찬가지로, 매치 프레이즈(phrase) 쿼리는 구(phrase)를 검색할 때 사용한다.
여기서 구(phrase)는 동사가 아닌 2개 이상의 단어가 연결되어 만들어지는 단어다.
아래의 예시를 보자.

검색어인 mary bailey가 토큰화되는 것까지는 매치 쿼리와 같지만, 용어의 순서까지 맞아야 한다.
그러면 한번 용어의 순서를 바꿔서 쿼리를 던져보자.

매치 프레이즈는 검색 시 많은 리소스를 요구하기 때문에, 자주 사용하는 것은 좋지 않다.
용어 쿼리
용어 쿼리는 용어 수준 쿼리의 대표적인 쿼리다.
사용 방법은 매치 쿼리와 비슷하나, mary bailey가 분석기에 의해 토큰화되지 않는다.


장난은 그만두고, Mary Bailey를 넣어보자.
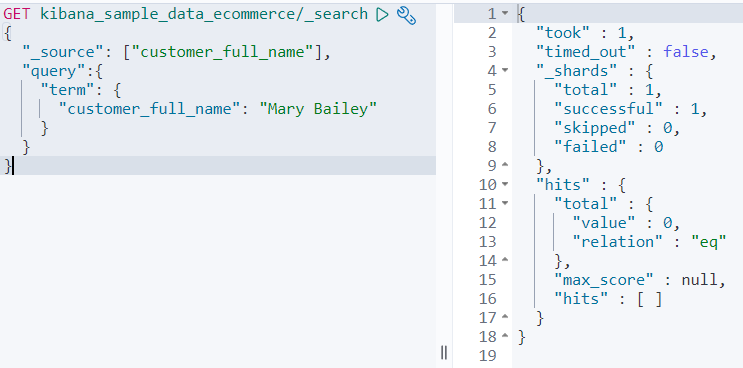
제대로 입력했는데도 검색이 안된다.
이는 customer_full_name 필드에서 mary, bailey로 토큰화가 되어있는데, 용어 쿼리는 Mary Bailey를 찾기 때문에 매칭이 되지 않기 때문이다.
이래서, 용어 수준 쿼리에서 필드를 키워드로 지정하는 것이다.
다행이, customer_full_name 필드는 텍스트와 키워드 타입을 가지는 멀티 필드로 지정되어 있다.
키워드 타입에서 용어 쿼리를 던져보자.

용어들 쿼리
용어들 쿼리는 여러 용어들을 검색해준다.

멀티 매치 쿼리
지금까지 쿼리를 이용해서 검색할 때는 반드시 필드명을 적어야 했다.
왜냐면, 엘라스틱서치는 필드를 기준으로 찾으려는 용어나 구절을 검색하기 때문이다. 하지만 가끔 우리는 검색하고자 하는 용어나 구절이 정확하게 어떤 필드에 있는지 모르는 경우가 있다.
... 쉽게 이해하기 위해서 예시를 들어보자.
네이버에 '사과'를 검색한다고 해보자. 그러면, 이 '사과'라는 단어가 어떠한 필드(블로그의 제목, 뉴스 기사, 쇼핑몰 etc)에 저장되어 있는지는 미지수이다.
이럴 경우, 하나의 필드가 아닌 여러 개의 필드에서 검색을 해야 한다.
여러 개의 필드에서 검색하기 위한 멀티 매치 쿼리는 전문 검색 쿼리의 일종으로, 텍스트 타입으로 매핑된 필드에서 사용하는 것이 좋다.

필드에 가중치를 두는 부스팅(Boosting) 기법도 있다.
아래의 예시를 보자.
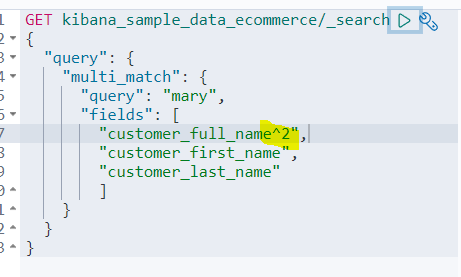
이렇게 하면 가중치를 부여할 수 있다.
저 ^2가 의미하는 것은 '가중치 배율'이다. customer_first_name이나 _last_name에서 얻은 스코어보다, _full_name에서 얻은 스코어가 2배 더 높게 책정된다.
대표 스코어는 각각의 필드에서 얻은 스코어 중에서 가장 큰 스코어로 정한다고 했는데, 이럴 경우 최종 대표 스코어는 customer_full_name에서 얻은 결과를 채택할 확률이 높아진다.
뭐... 이런 방식으로 사용된다.
범위 쿼리
특정 날짜나 숫자의 범위를 지정해 범위 안에 포함된 데이터들을 검색할 때 사용된다.
당연히, 문자형이나 키워드 타입의 데이터에는 범위 쿼리를 사용할 수 없다.
한번 날짜/시간 범위 쿼리 요청을 해보자.

참고로 책에서는 범위를 20201215 ~ 20201216으로 했는데, 샘플 데이터가 갱신되서 그런지 2022로 되어있다;
아무튼, 저런 방식으로 20221125 00:00:00 ~ 20221125 23:59:59인 데이터를 찾는다.
검색 범위를 지정하는 파라미터는 아래와 같다.
- gte: 이상(greater than + equal)
- gt: 초과(greater than)
- lte: 이하(less than + equal)
- lt: 미만(less than)
다음은 팁인데, 일주일 전 도큐먼트들이나 하루 전 도큐먼트들을 골라내서 쿼리를 진행하고 싶을 경우 더 편리하게 검색할 수 있는 표현식이 존재한다.
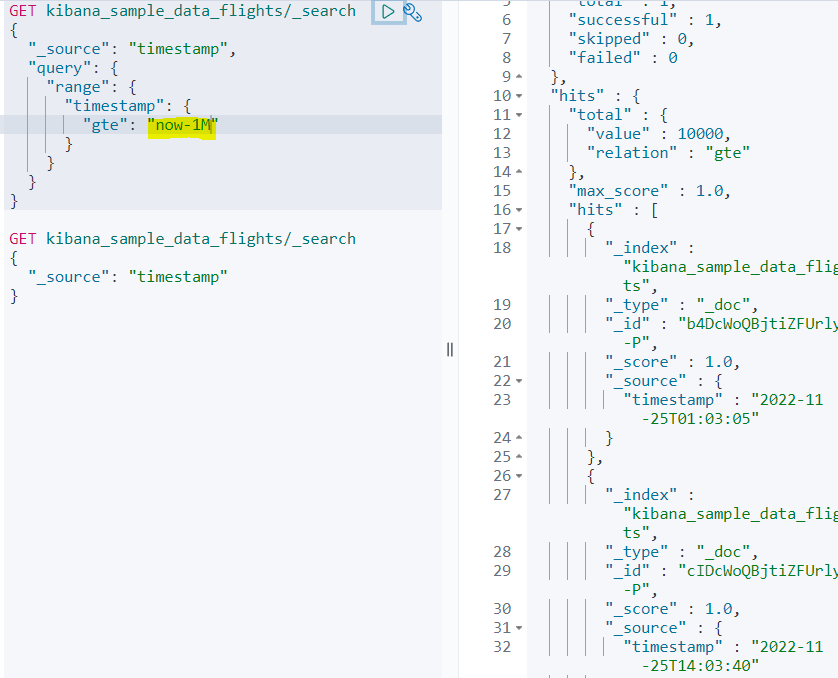
저기 now-1M은 현재 시각으로부터 1달 전 부터를 의미한다.
그러면 now+1M은 현재 시각으로부터 1달 후 부터겠지?

날짜/시간 관련 범위 표현식은 아래처럼 사용한다.
| 표현식 | 설명 |
| now | 현재 시각 |
| now+1d | 현재 시각 + 1일 |
| now+1h+30m+10s | 현재 시각 + 1시간 + 30분 + 10초 |
| 2021-01-21||+1M | 2021-01-21 + 1달 |
아래는 날짜/시간 단위 표기법이다.
| 시간 단위 | 의미 | 시간 단위 | 의미 | 시간 단위 | 의미 |
| y(year) | 연 | M(month) | 월 | w(weeks) | 주 |
| d(days) | 일 | H or h | 시 | m(minutes) | 분 |
| s(seconds) | 초 | 저 괄호 안에 있는건 표기법 설명. 괄호 밖에 있는 것이 표기법 | |||
6. 범위 데이터 타입
데이터 타입 중 범위 데이터 타입이 있다~고 언급만 했었는데, 한번 범위 데이터를 매핑해보자.

date_range 타입을 적용해보았고, 여기에 실제 값을 입력해보자.

이것으로 범위 데이터 타입을 이해....한건 아니고, 문제가 있다.
근데 이거 어떻게 검색함?
범위 데이터를 검색하기 위해서는, "relation"이라는 파라미터가 있어야 한다.
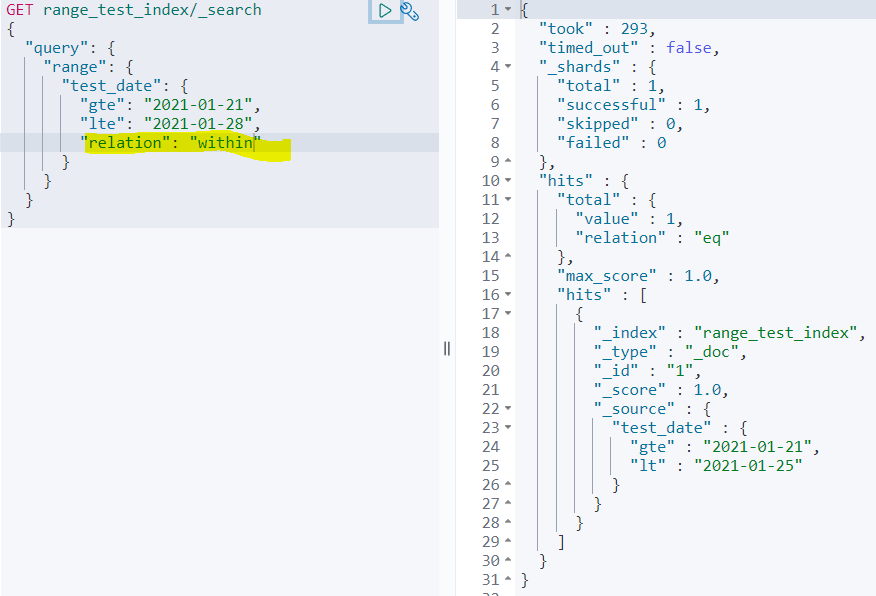
저 relation에 따라 검색하는 기준이 달라진다. 아래는 relation에 들어갈 수 있는 값들이다.
- intersects(기본값): 쿼리 범위 값이 도큐먼트 범위 데이터를 일부라도 포함하기만 하면 된다.
- contains: 도큐먼트의 범위 데이터가 쿼리 범위 값을 모두 포함해야 한다.
- within: 도큐먼트의 범위 데이터가 쿼리 범위 값 내에 전부 속해야 한다.
7. 논리 쿼리
논리 쿼리는 복합 쿼리로, 앞에서 배웠던 쿼리를 조합할 수 있다.
논리 쿼리는 쿼리를 조합할 수 있도록 4가지 타입을 지원한다.
GET <index>/_search
{
"query": {
"bool": {
"must": [{쿼리문}, ....],
"must_not": [{쿼리문}, ....],
"should": [{쿼리문}, ....],
"filter": [{쿼리문}, ....],
}
}
}저 4개의 타입에 대한 내용은 아래와 같다.
| 타입 | 설명 |
| must | 쿼리를 실행해 참인 도큐먼트를 찾는다. 복수의 쿼리를 실행하면 AND 연산을 한다. |
| must_not | 쿼리를 실행해 거짓인 도큐먼트를 찾는다. 다른 타입과 같이 사용 시 도큐먼트에서 제외한다. |
| should | 단독으로 사용 시 쿼리를 실행해 참인 도큐먼트를 찾는다. 복수의 쿼리를 실행하면 OR 연산을 한다. 다른 타입과 같이 사용할 경우 스코어에만 활용된다. |
| filter | 쿼리를 실행해 '예/아니오' 형식의 필터 컨텍스트를 수행한다. |
설명을 들어도 뭔가 감이 잘 안잡힌다.
한번 쿼리를 작성해야 이해가 될 것 같다.
must 타입
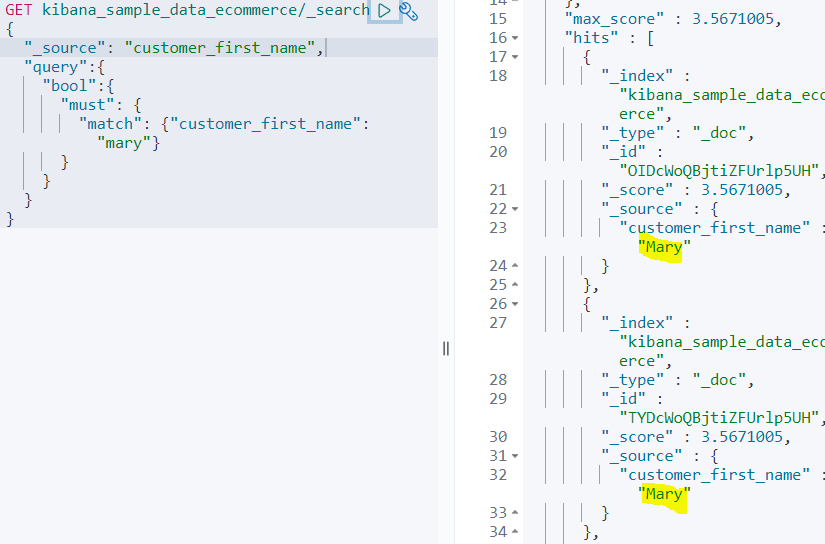
customer_first_name 필드에서 mary가 들어간 도큐먼트를 검색.
이제 복수 개의 쿼리를 사용해보자

이러면, customer_first_name이 mary이고, day_of_week가 Sunday인 도큐먼트만 검색한다.
두번째 _id를 잘 보면, 위와 다른 걸 볼 수 있다.
must_not 타입
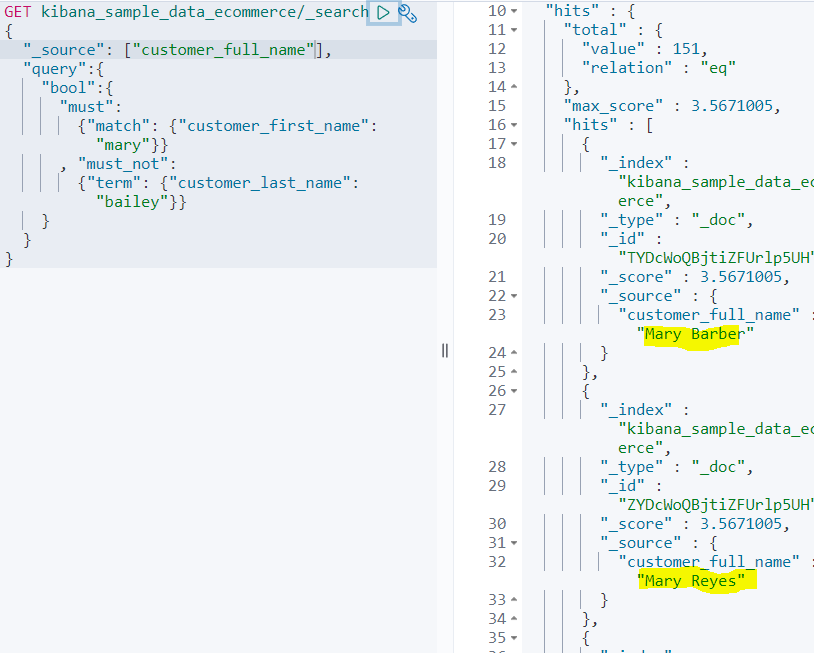
must_not 타입에 의해서 Mary Bailey는 검색되지 않는다.
should 타입
should는 must와 같은데 OR로 동작한다. 근데 이게 중요한게 아니고, should와 must 타입이 '동시에' 쓰이면 어떻게 되느냐다.

결론만 말하자면, should 타입 결과에 의한 도큐먼트들의 우선순위가 must 보다 높게 설정된다.
monday 도큐먼트들이 우선적으로 출력되고, 화면을 계속 아래로 내리면 mary 정보가 나타난다는 뜻.
filter 타입
위의 세 타입의 결과창을 잘 보면, '_score'가 있는 것을 볼 수 있다. 즉, 세 타입은 score를 계산한다는 뜻이다.
Filter 타입은 스코어를 계산하지 않는다.
따라서, 불필요한 스코어 계산을 줄이는 데에 사용된다.
(사용 방법은 must, should와 같다)
8. 패턴 검색
마지막으로, 검색어를 정확히 알지 못할 때 와일드카드와 정규식을 사용하는 방식이다. 각각 와일드카드 쿼리(wildcard query), 정규식 쿼리(regexp query)라고 부른다.
와일드카드 쿼리
와일드카드는 다른 dbms에서도 사용되어 익숙할테니, 요점만 짚자면
*는 글자 수 상관 없음, ?는 한 문자만 매칭.
와일드카드 쓸 때 주의할 점이 있는데, 검색하려는 용어 앞에 사용하면 속도가 매우 느려진다는 점이다.
정규식 쿼리
여기서 정규식 개념을 설명하기는 그렇고, 예시를 보여주는 것이 더 좋다고 생각한다.
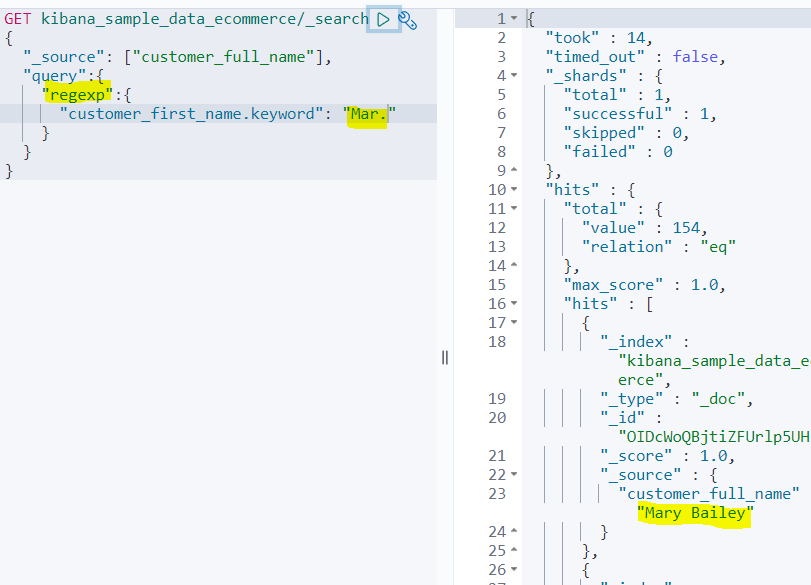
저 Mar.에서 '.'은 '공백을 제외한 하나의 문자'다. 거기에 해당되는 것이 바로 Mary다.
이것으로 검색 기능을 실습해봤다.
다음으로는 내가 원하는 데이터들을 넣고, 검색해보는 것을 수행해 볼 것이다.
'ElasticSearch' 카테고리의 다른 글
| 개인기록 - 오타교정 및 자동완성 (0) | 2022.11.15 |
|---|---|
| 엘라스틱서치 오타 교정, 자동 완성 등 구현 (0) | 2022.11.14 |
| 인덱스 템플릿과 분석기 (0) | 2022.11.09 |
| 엘라스틱서치 기본 (0) | 2022.11.09 |
| 엘라스틱 설치 다시시도 (0) | 2022.11.09 |