
1. 하둡 분산 파일 시스템 개요
HDFS는 수십 테라바이트 또는 페타바이트 이상의 대용량 파일을 분산된 서버에 저장하고, 많은 클라이언트가 저장된 데이터를 빠르게 처리할 수 있게 설계된 파일 시스템이다.
기존에도 DAS, NAS, SAN과 같은 대용량 파일 시스템이 있었으며, HDFS 또한 이러한 대용량 파일 시스템과 유사한 점이 많다. 우선, 위 3개의 대용량 파일 시스템을 알아보자.
| 명칭 | 특징 |
| DAS | Direct-Attached Storage. 서버에 직접 연결된 스토리지며, 외장형 하드디스크로 이해하면 된다. 여러 개의 하드디스크를 장착할 수 있는 외장 케이스를 이용하는 방식이다. |
| NAS | Network-Attached Storage. 일종의 파일 서버로, 별도의 운영체제를 사용하며 파일 시스템을 안정적으로 공유할 수 있다. 주로 첨부 파일이나 이미지 같은 데이터를 저장하는 데 많이 사용된다. |
| SAN | Storage Area Network. 수십에서 수백 대의 SAN 스토리지를 데이터 서버에 연결, 총괄적으로 관리해주는 네트워크를 의미. DAS의 단점 극복을 위해 개발되었으며, 현재 대부분의 시장을 차지하게 됨. DBMS와 같이 안정적이고 빠른 접근이 필요한 데이터를 저장하는 데 사용. |
HDFS가 위 시스템들과 다른 점은,
- 저사양 서버를 이용해 스토리지를 구성할 수 있음.
- 장애 복구: HDFS는 장애를 빠른 시간에 감지하고 대처할 수 있게 설계됨
- 스트리밍 방식의 데이터 접근: 랜덤 접근 방식 대신, 스트리밍 방식으로 데이터에 접근하도록 설계되어 끊김없이 연속된 흐름으로 접근할 수 있다.
- 대용량 데이터 저장: 높은 데이터 전송 대역폭과 하나의 클러스터에서 수백 대의 노드를, 하나의 인스턴스에서는 수백만개 이상의 파일을 지원한다.
- 데이터 무결성: 데이터베이스에 저장되는 데이터의 일관성으로, 입력이나 변경 등을 제한해 데이터의 안정성을 저해하는 요소를 막는다. 1.0버전에서는 수정을 전면적으로 막았지만, 2.0 버전부터는 append가 가능하게 했다.
2. HDFS 아키텍처
블록 구조 파일 시스템
- HDFS에 저장하는 파일은 특정 크기의 블록으로 나눠져 분산된 서버에 저장된다.
- 블록 크기는 기본적으로 64MB로 설정되어 있으며, 그 이유는 다음과 같다.
- 디스크 시크 타임(seek time) 감소: 디스크 탐색 시간은 데이터의 위치를 찾는 시크 타임(seek time)과 데이터의 섹터에 도달하는 데 걸리는 시간인 서치 타임(search time)의 합이다. 이 중 시크 타임을 감소시키기 위해 64MB로 설정...했으나 기술의 발달로 2.0 버전부터는 128MB로 늘어났다.
- 네임노드가 유지하는 메타데이터의 크기 감소: 네임노드는 블록의 위치, 파일명, 디렉터리의 구조, 권한 정보와 같은 메타데이터를 메모리에 저장하고 관리한다. 기본 블록 크기보다 작은 파일을 저장하면, 네임노드가 사용할 수 있는 블록 개수도 빠르게 줄기 때문에, 이를 막기 위해서 블록의 크기를 작게 설정한 것이다.
- 클라이언트와 네임노드의 통신 감소: 클라이언트가 HDFS에 저장된 파일을 접근할 때 네임노드에서 해당 파일을 구성하는 블록의 위치를 조회한다 클라이언트는 스트리밍 방식으로 데이터를 읽고 쓰므로 특별한 경우를 제외하고는 네임노드와 통신할 필요가 없어진다.
네임노드와 데이터노드
HDFS는 마스터-슬레이브 아키텍처로, 마스터 서버는 네임노드(Name Node), 슬레이브 서버는 데이터노드(DataNode)다.
우선, HDFS의 마스터 서버인 네임노드는 다음과 같은 기능을 수행한다.
- 메타데이터 관리: 파일 시스템 이미지(파일명, 디렉터리, 크기, 권한)와 파일에 대한 블록 매핑 정보로 구성된다. 네임노드는 클라이언트에게 빠르게 응답할 수 있도록 메모리에 전체 메타데이터를 로딩해 관리한다.
- 데이터노드 모니터링: 네임노드에게 3초마다 하트비트(HeartBeat) 메시지를 전송한다. 하트비트는 데이터노드 상태 정보와 데이터노드에 저장되어 있는 블록의 목록(blockreport, 블록리포트)으로 구성된다. 이 하트비트를 이용해 데이터노드를 모니터링한다.
- 블록 관리: 장애가 발생한 데이터노드 발견 시 해당 데이터노드의 블록을 새 데이터노드로 복제한다. 또한, 용량이 부족한 데이터노드가 있으면 용량에 여유가 있는 데이터노드로 블록을 이동시킨다. 또 복제본 수와 일치하는 블록이 발견되면 추가로 블록을 복제 or 삭제한다.
- 클라이언트 요청 접수: 클라이언트가 HDFS에 접근하려면 반드시 네임노드에 먼저 접속해야 한다. HDFS에 파일을 저장하는 경우 기존 파일의 저장 여부와 권한 확인의 절차를 거쳐 저장을 승인한다. 또한, HDFS에 저장된 파일을 조회하는 경우 블록의 위치 정보를 반환한다.
데이터노드는 클라이언트가 HDFS에 저장하는 파일을 로컬 디스크에 유지한다. 이때 로컬 디스크에 저장되는 파일은 크게 두 종류로, 실제 데이터가 저장되어 있는 로우 데이터(raw data), 다른 하나는 체크섬(Checksum)이나 파일 생성 일자와 같은 메타데이터가 설정되어 있는 파일이다.
3. HDFS의 파일 저장
1. 클라이언트가 네임노드에게 파일 저장을 요청하는 단계
- 클라이언트는 DistributedFileSystem의 create 메서드를 호출해 스트림 객체를 생성(스트림 요청)
- DistributedFileSystem은 DFSClient의 create 메서드 호출해 DFSOutputStream(스트림)을 생성
- DFSClient는 네임노드의 create 메서드 호출해 클라이언트의 요청이 유효한지 검사 진행, 정상이면 파일 시스템 이미지에 해당 파일의 엔트리 추가하고 클라이언트에게 해당 파일 저장할 수 있는 제어권 부여
- DFSOutputStream 객체가 정상적으로 생성, 이를 래핑한 FSDataOutputStream을 클라이언트에게 반환.
2. 클라이언트가 데이터노드에게 패킷을 전송하는 단계
- 클라이언트는 스트림 객체의 write 메서트를 호출해 파일 저장 시작. DFSOutputStream은 클라이언트가 저장하는 파일을 64K 크기의 패킷으로 분할
- 전송할 패킷을 내부 큐인 데이터큐(DataQueue)에 등록, 등록이 확인되면 DataStreamer(DFSOutputStream의 내장 클래스)는 네임노드의 addBlock 메서드를 호출
- 네임노드는 블록을 저장할 데이터노드 목록을 반환(복제본 수와 동일한 수의 데이터노드를 연결한 파이프라인을 형성함).
- DataStreamer는 파이프라인의 첫 번째 데이터노드부터 패킷 전송 시작. 데이터노드는 클라이언트와 다른 데이터노드로부터 패킷을 주고받기 위해서 DataXceivverServer 데몬(패킷 교환 기능 제공) 실행.
- 각 데이터노드는 패킷이 정상적으로 저장되면 자신에게 패킷을 전송한 데이터노드에게 ACK 메시지를 전송. ACK 메시지는 파이프라인을 통해 DFSOutputStream에게 전달됨
- 패킷 저장 완료 시 네임노드의 blockReceived 메서드 호출. 네임노드가 '정상적으로 저장됨'을 인지하게 함
- DFSOutputStream(의 내부 스레드인 ResponseProcessor)가 모든 데이터노드로부터 승인 메시지를 받으면, 해당 패킷을 승인큐에서 제거. 만약 장애가 발생했다면 승인 큐에 있는 모든 패킷을 다시 데이터큐로 이동해 다시 전송 작업 수행.
3. 클라이언트가 파일 저장을 완료하는 단계
스트림을 닫고 파일 저장을 완료할 차례.
- 클라이언트는 DirstributedFileSystem의 close 메서드 호출해 파일 닫기 요청
- DFS는 DFSOutputStream의 close 메서드 호출, DFSOutputStream에 남아 있는 모든 패킷을 파이프라인으로 플러시(flush).
- DFSOutputStream은 네임노드의 complete 메서드 호출해 패킷이 정상적으로 저장되었는지 확인.
4. HDFS의 파일 조회
1. 파일 조회 요청
- 클라이언트는 DistributedFileSystem의 open 메서드를 호출해 스트림 객체 생성 요청
- DFS는 FSDataInputStream 객체 생성해 DFSDataInputStream과 DFSInputStream을 차례대로 래핑. 이때 DFSInputStream을 생성하기 위해서 DFSClient의 open 메서드 호출
- DFSClient는 DFSInputStream을 생성.
- 네임노드는 조회 대상 파일의 블록 위치 목록 생성 후, 목록을 클라이언트에 가까운 순으로 정렬. 정렬 완료 시 DFSInputStream에 정렬된 블록 위치 목록을 반환. DistributedSystem은 이 DFSInputStream을 이용해 FSDataInputStream로 생성해 클라이언트에게 반환.
| 클라이언트 | DistributedFilsSystem | DFSClient | 네임노드 |
| open 메서드 호출, Stream 요청 | FSDataInputStream 생성 | DFSInputStream 생성 | 블록 위치 목록 생성 |
2. 블록 조회
- 클라이언트는 입력 스트림 객체의 read 메서드 호출
- DFSInputStream은 첫 번째 블록과 가장 가까운 데이터노드 조회, 블록을 조회하기 위한 리더기(reader) 생성. 위치에 따라서 BlockReaderLocal(로컬)을 생성하거나 RemoteBlockReader(원격)을 생성
- DFSInputStream은 리더기의 read 메서드를 호출해 블록을 조회.
- DFSInputStream은 파일을 모두 읽을 때까지 계속해 블록을 조회, 만약 DFSInputStream이 저장하고 있던 블록을 모두 읽었는데도 파일을 모두 읽지 못하면 네임노드의 getBlockLocations를 호출하여 필요한 블록 위치 정보를 다시 요청한다.
- 네임노드는 DFSInputStream에게 클라이언트에게 가까운 순으로 정렬된 블록 위치 목록을 반환한다.
3. 입력 스트림 닫기
클라이언트가 모든 블록을 읽고 나면 입력 스트림 객체를 닫아야 한다.
- 클라이언트는 입력 스트림 객체의 close 메서드를 요청해 스트림 닫기를 요청한다.
- DFSInputStream은 데이터 노드와 연결되어 있는 커넥션을 종료. 그리고 블록 조회용으로 사용했던 리더기도 닫음.
5. 보조네임노드
네임노드는 메타데이터를 메모리에서 처리하는데, 메모리에서만 데이터를 유지하면 서버가 재부팅될 때 메타데이터 유실 가능성이 있다. 이 문제를 극복하기 위해서 editslog와 fsimage라는 두 파일을 생성한다.
- editslog: HDFS의 모든 변경 이력을 저장. 클라이언트가 파일을 저장하거나 삭제, 이동시 이를 기록.
- fsimage: 메모리에 저장된 메타데이터의 파일 시스템 이미지를 저장한 파일.
네임노드가 구동될 경우, 다음과 같은 단계로 두 개의 파일을 사용한다.
- 네임노드 구동 시, 로컬에 저장된 fsimage와 editslog 조회
- 메모리에 fsimage 로딩하여 파일 시스템 이미지 생성
- 메모리에 로딩된 파일 시스템 이미지에 editslog에 기록된 변경 이력을 적용
- 메모리에 로딩된 파일 시스템 이미지를 이용해 fsimage를 다시 갱신
- editslog를 초기화
- 데이터노드가 전송한 블록리포드(BlockReport)를 메모리에 로딩된 파일 시스템 이미지에 적용한다.
위 단계는 평상시에는 문제가 없지만 editslog의 크기가 크면 문제가 된다. 이런 문제를 해결하기 위해서 HDFS는 보조 네임 노드(Secondary Name Node)라는 노드를 제공한다. 보조네임노드는 주기적으로 네임노드의 fsimage를 갱신하는 역할을 하며, 이러한 작업을 체크포인트라고 한다.
이 작업은 다음과 같은 단계를 거친다.
- 보조네임노드는 네임노드에게 editslog를 롤링(현재 로그 파일의 이름을 변경하고 원래 이름으로 새 로그 파일을 만드는 것)할 것을 요청
- 네임노드는 기존 editslog를 롤링, editslog.new를 생성
- 보조네임노드는 네임노드에 저장된 (롤링된) editslog와 fsimage를 다운로드한다.
- 다운받은 fsimage를 메모리에 로딩하고, editslog에 있는 변경 이력을 메모리에 로딩된 파일 시스템 이미지에 적용한다. 메모리 갱신이 완료되면 새로운 fsimage(fsimage.ckpt)를 생성하며, 이 파일을 체크포인팅할 때 사용한다.
- 보조네임노드는 fsimage.ckpt를 네임노드에게 전송한다.
- 네임노드는 로컬에 저장되어 있던 fsimage를 보조네임노드가 전송한 fsimage.ckpt로 변경하고, editslog.new 파일명을 editslog로 변경한다.
체크포인트 작업이 완료되면 fsimage는 최신 내역으로 갱신되며 editslog의 크기도 축소된다. 체크포인트 작업은 하둡 환경설정 파일에서 fs.checkpoint.period 값을 수정해 제어할 수 있다.
보조네임노드는 네임노드의 fsimage를 축소시켜주는 역할을 담당할 뿐 백업 서버가 아니다.
6. HDFS 명령어
하둡은 사용자가 HDFS를 쉽게 사용할 수 있게 셸 명령어를 제공한다.
이 셸 명령어를 FileSystemShell(fs)라고 하며, 아래와 같은 형식으로 실행할 수 있다.
./bin/hadoop fs -cmd [args]
bashrc에서 설정하면, ./bin/hadoop 대신 hadoop만 사용할 수 있다.
아무튼, fs 셸에서 어떤 기능을 제공하는지 알아보자.
파일 목록 보기 - ls, lsr
ls : 지정한 디렉터리에 있는 파일의 정보를 출력하거나, 특정한 파일을 지정해 정보를 출력하는 명령어다. 파일 및 디렉터리의 권한 정보, 소유자, 소유 그룹, 생성일자, 바이트 수 등을 확인할 수 있다.

처음 하둡을 실행하면 홈 디렉터리에 아무것도 없어서 확인이 불가능하니, 파일을 한번 생성해보자.
위와 같은 상황에서, 저 README.txt를 하둡 디렉터리로 복사할 것이다.
우선, 아래 명령어로 dir1 디렉터리를 생성해보자.

그리고, 아래 명령어로 dir1 디렉터리에 README.txt를 복사해보자.

명령어는 각각 다음과 같다.
hadoop fs -mkdir /dir1
hadoop fs -copyFromLocal README.txt /dir1
그리고, 다음과 같이 ls를 실행해보자
hadoop fs -ls /dir1

디렉터리에 저장되어 있는 파일 목록이 출력되는 것을 볼 수 있다.
lsr: 현재 디렉터리의 하위 디렉터리 정보까지 출력한다.
다음과 같이 하위 디렉터리를 생성해보자
hadoop fs -mkdir /dir1/dir2
hadoop fs -copyFromLocal NOTICE.txt /dir1/dir2

이제, dir1에서 lsr를 사용해 모든 정보를 출력해보자.
hadoop fs -lsr /dir1
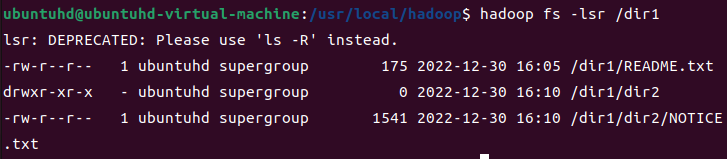
파일 용량 확인 - du, dus
du: 지정한 디렉터리나 파일의 사용량을 확인하는 명령어다.
hadoop fs -du /dir1

dus: 전체 합계 용량만 출력한다.
hadoop fs -dus /dir1

파일 내용 보기 - cat, text
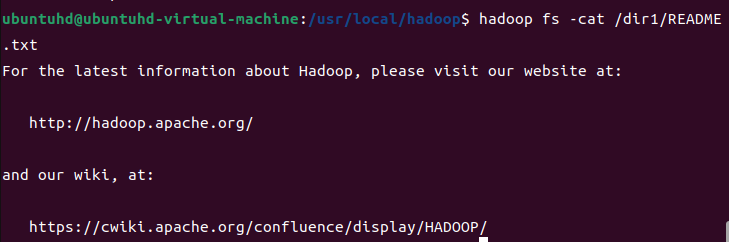
cat: 지정한 파일의 내용을 화면에 출력한다.
hadoop fs -cat /dir1/README.txt
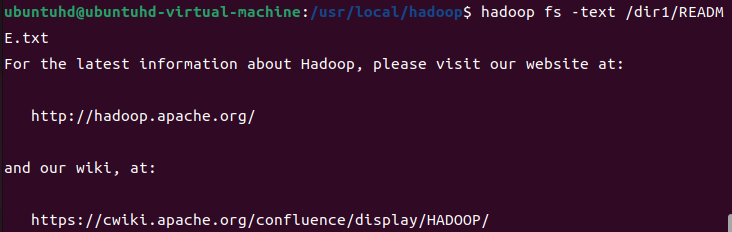
text: cat 명령어는 텍스트 파일만 출력할 수 있다. 하지만, text 명령어는 zip 파일 형태로 압축된 파일도 텍스트 형태로 화면에 출력한다. 나중에 맵리듀스를 살펴볼 때 압축된 형식으로 출력 데이터를 생성하게 되는데, 이때는 text 명령어를 사용해 데이터를 확인한다.
지금은 그런 파일이 없으니, README.txt에 text를 사용해보자.
hadoop fs -text /dir1/README.txt
디렉터리 생성 - mkdir
지정한 경로에 디렉터리를 생성한다. 위에서 dir1을 이 mkdir로 생성해봤으니, 생략한다.
파일 복사 - put, get, getmerge, cp, copyFromLocal, copyToLocal
put, copyFromLocal - 지정한 로컬 파일 시스템의 파일 및 디렉터리를 목적지 경로로 복사한다.
'로컬' 파일 시스템이니, '로컬'의 파일들을 확인해보자.

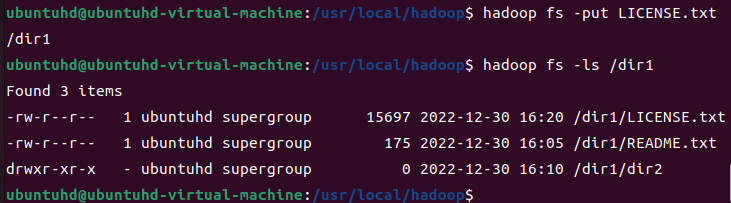
로컬의 LICENSE.txt를 /dir1로 이동시켜보자. 그리고, /dir1을 확인해보자.
hadoop fs -put LICENSE.txt /dir1
hadoop fs -ls /dir1
get, copyToLocal: HDFS에 저장된 데이터를 로컬 파일 시스템으로 복사한다.
여기서 단순하게 복사만 하는건 아니다. HDFS는 파일의 무결성 확인을 위해서 체크섬 기능을 사용하는데, 체크섬을 숨김 파일로 저장하고, 해당 파일을 조회할 때 체크섬을 이용해 무결성을 확인한다. get 명령어를 실행할 때 -crc 옵션을 사용하면 로컬 파일 시스템에 체크섬 파일도 복사된다. -ignoreCrc 옵션을 이용하면 해당 파일의 체크섬을 확인하지 않는다.
...요약하자면, get 메서드에는 체크섬(CheckSum)이 관여된다고 생각하면 된다.
우선, README.txt를 ~ 위치로 이동해 저장하도록 하자.
cd ~
ls

이제, 여기에 README.txt를 가져오자.
hadoop fs -get /dir1/README.txt .
ls

getmerge: 지정한 경로에 있는 모든 파일의 내용을 합친 후, 로컬 파일 시스템에 단 하나의 파일로 복사한다.
설명만 들으면 이해가 안되지만, 다음 예시를 보면 한눈에 알 수 있다.
hadoop fs -getmerge /dir1 MERGE.txt
gedit MERGE.txt

getmerge 명령어에 의해서, /dir1 경로에 존재하는 README.txt와 LICENSE.txt가 합쳐저 MERGE.txt가 된다.
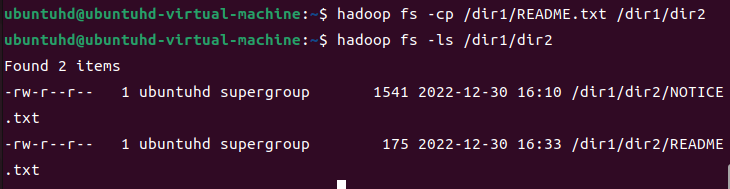
cp: 지정한 소스 디렉터리 및 파일을 목적지 경로로 복사하는 기능이다.
README.txt를 dir2로 복사해보자.
hadoop fs -cp /dir1/README.txt /dir1/dir2
hadoop fs -ls /dir1/dir2
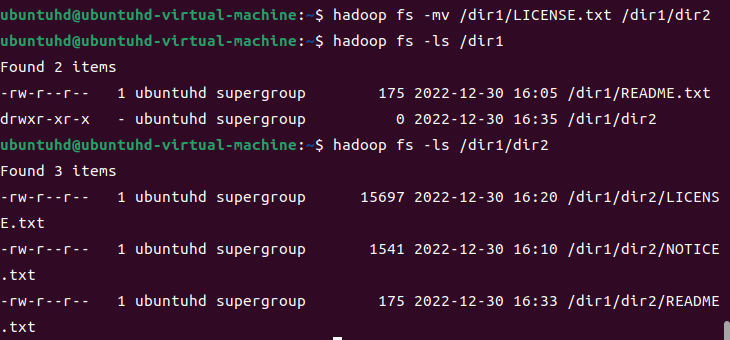
파일 이동 - mv, moveFromLocal
mv: 소스 디렉터리 및 파일을 목적지 경로로 옮긴다.
LICENSE.txt를 dir2로 옮겨본다.
hadoop fs -mv /dir1/LICENSE.txt /dir1/dir2
hadoop fs -ls /dir1
hadoop fs -ls /dir2
moveFromLocal: put(copyToLocal) 명령어와 동일하게 동작하나, 복사된 후 기존 경로의 파일은 삭제된다.
로컬의 MERGE.txt를 /dir1/dir2로 옮겨보자.
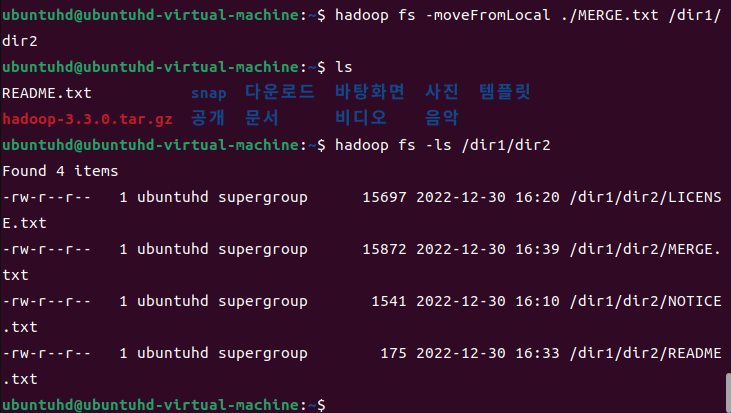
hadoop fs -moveFromLocal ./MERGE.txt /dir1/dir2
ls
hadoop fs -ls /dir1/dir2
파일 삭제 - rm
지정한 디렉터리나 파일을 삭제할 수 있다. 디렉터리를 삭제할 때는 반드시 비어 있는 경우에만 삭제할 수 있다.
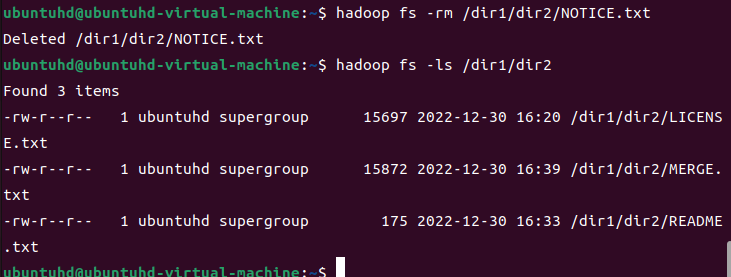
/dir1/dir2의 NOTICE.txt를 삭제해보자.
hadoop fs -rm /dir1/dir2/NOTICE.txt
hadoop fs -ls /dir1/dir2
디렉터리 삭제 - rmr
지정한 파일 및 디렉터릴르 삭제한다. 비어있지 않은 디렉터리도 정상적으로 삭제할 수 있는...데
위험하니 기왕이면 사용을 자제하는 것이 좋다
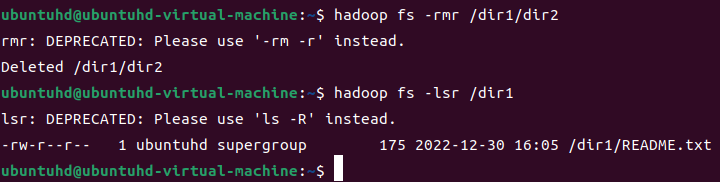
/dir1/dir2 디렉터리를 삭제해보자.
hadoop fs -rmr /dir1/dir2
hadoop fs -lsr /dir1
카운트값 조회 - count
기본적으로 지정한 경로에 대한 전체 디렉터리 개수, 전체 파일 개수, 전체 파일 크기, 지정한 경로명을 출력한다. HDFS는 디렉터리에서 생성할 수 있는 파일 개수나 용량을 제한할 수 있다.
dir1에 카운트값을 조회해보자,.
hadoop fs -count /dir1
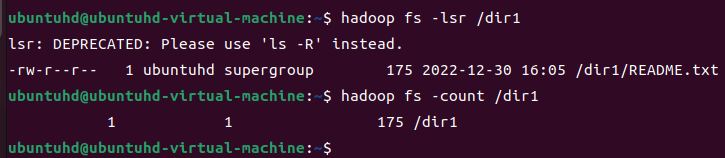
위의 실행 결과로, /dir1의 정보는 다음과 같음을 알 수 있다.
- 전체 디렉터리 개수: 1
- 전체 파일 개수: 1
- 전체 파일 크기: 175
- 지정한 경로명: /dir1
파일 마지막 내용 확인 - tail
지정한 파일의 마지막 1KB에 해당하는 내용을 화면에 출력한다. -f 옵션을 사용하면 해당 파일에 내용이 추가될 때 화면에 출력된 내용도 함께 갱신된다.
hadoop fs -tail /dir1/README.txt
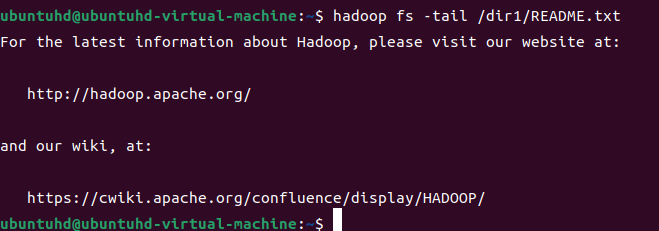
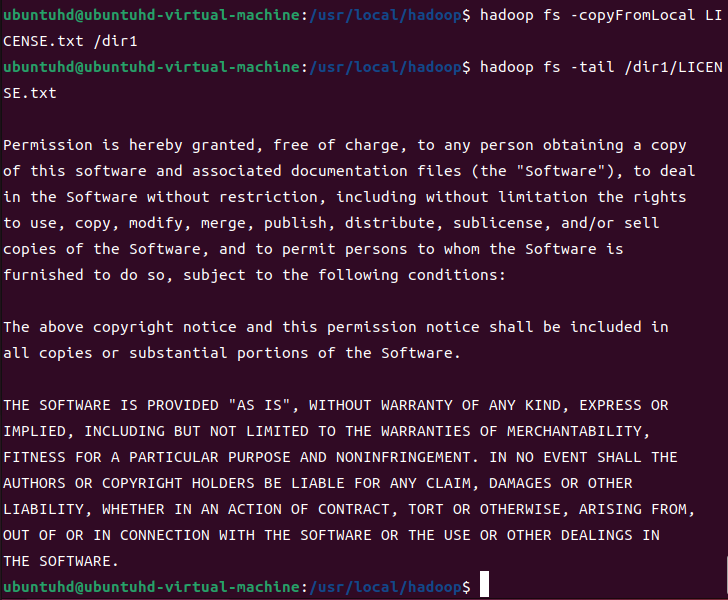
이래서는 tail의 의미가 없으니, LICENSE.txt를 가져와서 수행해본다.
(수행하기 전, LICENSE.txt가 있는 위치로 이동한다)
hadoop fs -copyFromLocal LICENSE.txt /dir1
hadoo fs -tail /dir1/LICENSE.txt
권한 변경 - chmod, chown, chgrp
chmod: 지정한 경로에 대한 권한을 변경한다. 권한 모드는 숫자로 표기하는 8진수 표기법 혹은 영문으로 표기하는 심볼릭 표기법으로 설정할 수 있는데, 유닉스 계열 시스템에서 권한 변경하는 것과 같으니 여기서는 자세히 설명하지는 않겠다.

지금 이렇게 되어 있는데, 모든 사용자가 README.txt 파일을 읽고, 쓰고, 실행할 수 있도록 권한을 부여해보겠다.
hadoop fs -chmod 777 /dir1/README.txt
hadoop fs -ls /dir1

chown: 지정한 파일과 디렉터리에 대한 소유권을 변경하는 명령어다. -R 옵션을 사용하면, 재귀적으로 명령어가 실행되 하위 디렉터리의 설정도 모두 변경된다.
소유자명과 그룹명을 표기할 때, [변경 사용자 명: 변경 그룹 명]의 형태로 표기해야 한다.
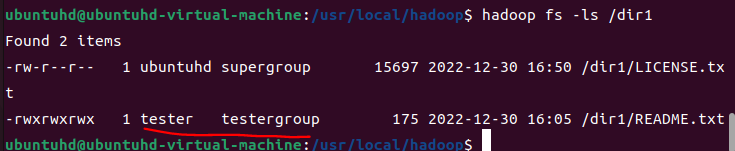
모든 사용자가 편집할 수 있는 README.txt의 소유자를 tester로, 소유 그룹을 testergroup으로 변경한다.
hadoop fs -chown tester:testergroup /dir1/README.txt
hadoop fs -ls /dir1
chgrp: 소유권 그룹(group)만 변경한다. chown과 마찬가지로 -R 옵션 사용 시 하위 디렉터리 정보도 모두 변경된다.
README.txt를 다시 supergroup으로 소유권 그룹을 변경해보자.
hadoop fs -chgrp supergroup /dir1/README.txt
hadoop fs -ls /dir1

0바이트 파일 생성 - touchz
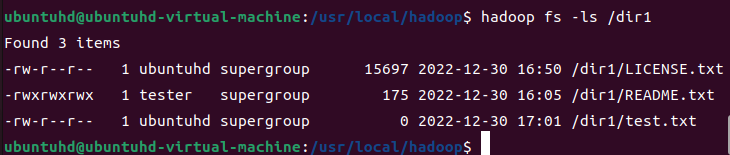
크기가 0바이트인 파일을 생성한다. 지정한 파일명이 이미 0바이트 이상인 상태로 저장되어 있으면 오류가 발생하니 주의할 것.
hadoop fs -touchz /dir1/test.txt
hadoop fs -ls /dir1
통계 정보 조회 - stat
지정한 경로에 대한 통계 정보를 조회한다. 별도의 옵션을 사용하지 않으면 해당 디렉터리 혹은 파일이 최종 수정된 날짜를 출력한다.
stat 명령어에서 사용 가능한 옵션은 아래와 같다.
| 옵션 | 내용 |
| %b | 블록 단위의 파일 크기 |
| %F | 디렉터리면 'directory', 일반 파일이면 'regular file' 출력 |
| %n | 디렉터리명 or 파일명 |
| %o | 블록 크기 |
| %r | 복제 파일의 개수 |
| %y | 디렉터리 및 파일 갱신 일자를 yyyy-MM-dd HH:mm:ss 형식으로 출력 |
| %Y | 디렉터리 및 파일 갱신일자를 유닉스 타임스탬프 형식으로 출력 |
다음 3가지를 실행해보자.
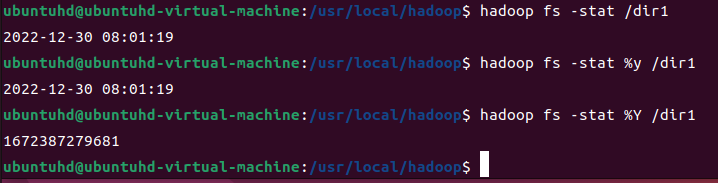
hadoop fs -stat /dir1
hadoop fs -stat %y /dir1
hadoop fs -stat %Y /dir1
복제 데이터 개수 변경 - setrep
설정한 파일의 복제 데이터 개수를 변경할 수 있다.
우선, README.txt의 복제 데이터 개수를 확인해보자.
hadoop fs -stat %r /dir1/README.txt

복제 데이터를 2개로 변경하고 다시 확인해보자.
hadoop fs -setrep -w 2 /dir/README.txt
hadoop fs -stat %r /dir1/README.txt


휴지통 비우기 - expunge
휴지통을 비운다. HDFS에서는 삭제한 파일을 .Trash/라는 임시 디렉터리에 저장한 다음에 일정 시간이 지난 후 완전히 삭제한다. 사용자는 이런 휴지통 기능을 환경설정 파일에서 설정할 수 있다. expunge 명령어를 사용할 경우, 설정된 휴지통 데이터 삭제 주기와 상관없이 휴지통에 있는 데이터를 모두 삭제한다.

7. 클러스터 웹 인터페이스
하둡은 HDFS의 기본적인 상태를 모니터링하고 HDFS 내에 저장된 파일을 조회할 수 있게 웹 인터페이스를 제공한다. 물론 사용자가 웹 인터페이스를 이요할 수 있게 자체적인 웹 서버를 구동한다.
localhost:9870으로 접속하면 이를 확인해볼 수 있다.
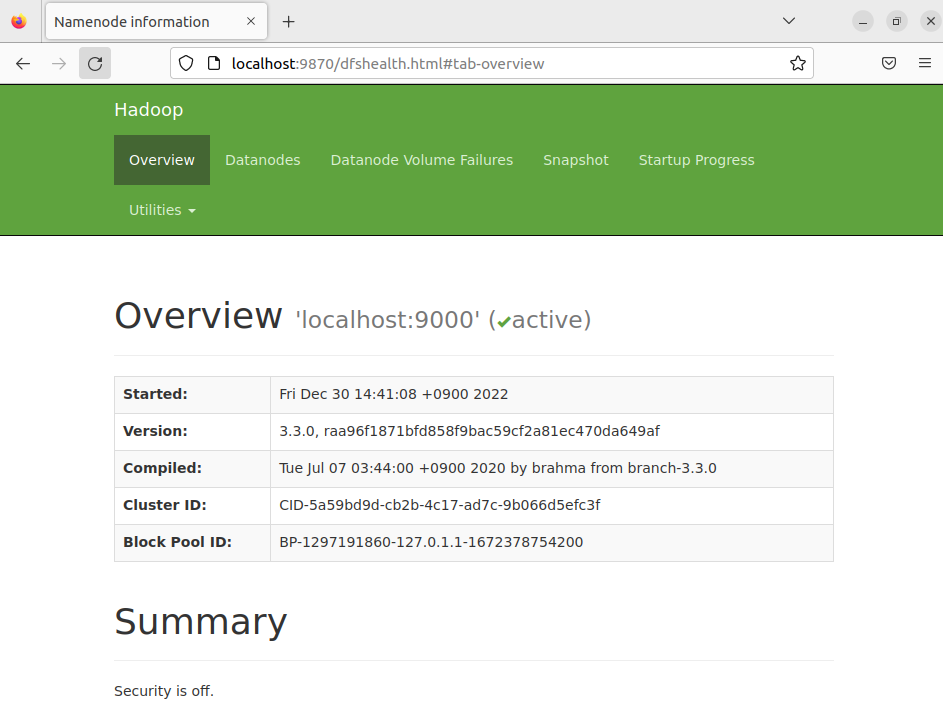
네임노드의 구동 일자, 버전 정보, 컴파일 정보, 클러스터 ID, 블록 풀 ID를 볼 수 있다.
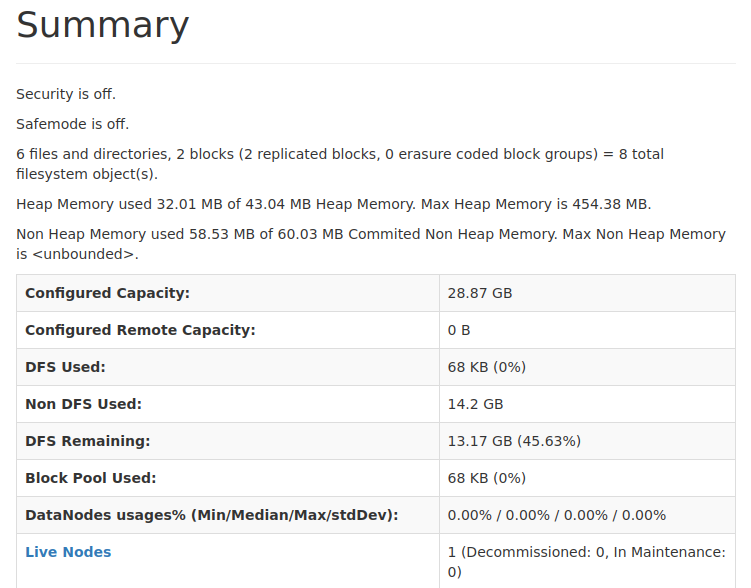
여기서는 현재 저장된 파일과 디렉터리 수, 디스크 사용량 등을 확인할 수 있다.
HDFS에 대해서 알아보았으니 다음에는 맵리듀스를 다루어보자.