
NOSQL 등장 배경
1) 2000년대 들어서면서 인터넷의 발전과 함께 sns 서비스가 활성화
2) 한정된 규모의 복잡성이 높은 데이터를 취급하는 기존 기업 시스템에서 볼 수 없었던 대규모 데이터를 생산
3) 이러한 데이터들은 기존 기업 데이터에 비해 매우 단순한 형태를 가짐
- 기존의 데이터 저장 시스템으로는 커버 불가능해서, 새로운 형태의 데이터 저장 기술을 요구하게 됨
4) 구글과 아마존에 의해 빅테이블(Bigtable)과 Dynamo라는 논문이 발표되는데, 이 두 논문이 새로운 데이터 저장 기술인 NoSQL이 등장하는 계기가 됨
5) 관계형 데이터베이스인 RDBMS가 데이터의 관계를 Foreign Key 등으로 정의하고 이를 이용해 Join 등의 관계형 연산을 하지만, NoSQL은 데이터 간의 관계를 정의하지 않음
6) RDBMS의 복잡도와 용량 한계를 극복하기 위한 목적으로 등장한 만큼, 대용량 데이터를 저장할 수 있다.
NOSQL은?
nosql은 Not Only SQL 혹은 Non-Relational Operational DB SQL으로 부른다(주로 전자로).
즉, 기존 RDBMS 형태의 관계형 데이터베이스가 아니라 다른 형태의 데이터 저장 기술을 의미한다.
주요한 특징으로, 대규모의 데이터를 유연하게 처리할 수 있다.
앞서 설명한대로, 자주 변경하지 않거나 로그데이터처럼 데이터를 쌓는 경우에 사용한다.
| 데이터베이스 | 종류 | DATABASE |
| 관계형 DB | 관계형 DB | ORACLE, MYSQL |
| NOSQL DB | Key-Value DB | Redis, Riak |
| Document DB | MongoDB, Couch DB | |
| Column Family DB | Cassandra, HBASE | |
| Graph DB | Neo4j, OrientDB |
기존의 RDBMS의 경우 [write > 50%]인 경우, 성능 저하 및 불안정을 야기한다. NoSQL은 데이터가 수십만개씩 쌓여도 감당 가능하다.
- NOSQL은 기존의 RDBMS처럼 하나의 고성능 머신에 데이터를 저장하는게 아니라, 일반적인 서버(Commodity Server) 수십대를 연결해 데이터를 저장 및 처리한다.
- 분산형 구조를 통해 데이터를 여러 대의 서버에 분산 저장하고, 분산 시에 데이터를 상호 복제해 특정 서버에 장애가 발생하더라도 데이터 유실이나 서비스 중지가 없는 형태를 띈다.
- 또한, NoSQL은 RDBMS와 다르게 테이블의 스키마가 유동적이다. ID로 사용하는 키 부분에만 타입이 동일하고, 생략되지 않는 필드로 지정하면 값에 해당하는 컬럼은 어떤 타입이든, 어떤 이름이 오든 허용된다. 즉, ID 필드는 공통이나 데이터를 저장하는 컬럼은 각기 다른 이름과 다른 데이터 타입을 가질 수 있다.
RDBMS에서 가장 중요하게 여기는 성질은 ACID(Atomicity:원자성, Consistency:지속성, Isolation:독립성, Durability:영속성)이고, NoSQL에서는 CAP(Consistency: 지속성, Availability: 가용성, Partitioning: 부분결함 용인)이다.
- Consistency(일관성): 모든 노드가 같은 시간에 같은 데이터를 보여줘야 함
- Availability(가용성): 몇몇 노드가 다운되어도, 다른 노드들에게 영향을 주지 않아야 한다.
- Partitioning(부분결함 용인): 일부 메시지가 손실되더라도 시스템은 정상 동작을 해야 한다.
중요한 점은, 이 3가지를 모두 만족시킬 수는 없다는 점이다. CAP 이론은 이 중 2개만 만족할 수 있다는 것이 특징이다.
Key/Value Store
대부분의 NoSQL은 Key Value 개념을 지원한다. 주로 Unique Key에 하나의 Value를 가지는 형태인데, 아래와 같은 성질을 띈다.
| - put(key, value) - value := get(key) |
이 중 MongoDB에서 사용하는 Document Key/Value Store형태는 위에서 확장된 형태이다.
저장되는 value의 데이터 타입으로 'Document'라는 구조화된 데이터타입을 사용해 복잡한 계층 구조를 JSON 형식으로 저장한다.
제품에 따라 Sorting, Join, Grouping 등 다양한 기능을 지원한다.
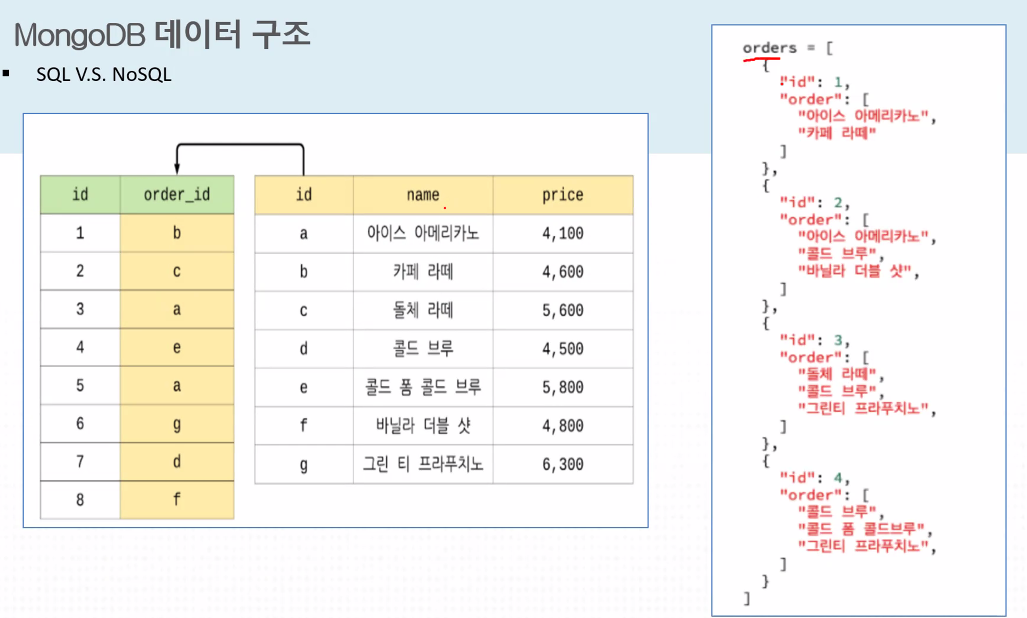
Mongo DB의 데이터 계층 구조는 아래와 같다.

RDBMS, NOSQL의 장점/단점
RDBMS 장점
- 범용적이고 고성능
- 데이터의 일관성을 트랜잭션으로 보증 가능
- 한번에 이루어져야 하는 작업에서 데이터불일치 상황을 방지
- 정규화를 전제로 하므로 업데이트시 비용이 적다
- 데이터베이스 설계시 이미 불필요한 중복이 삭제됨
- 복잡한 형태의 쿼리도 가능하며, 이미 성숙한 기술이다.
RDBMS 단점
- 데량의 데이터 입력 처리가 힘들다
- 테이블의 인덱스 생성이나 스키마 변경이 힘들다
- 개발 및 운영 시 칼럼을 확정짓기 어려울 수 있다
NOSQL 장점
- NOSQL은 특정 용도에 맞게 특화되어 있다
- 데이터모델 자체가 독립적으로 설계되어 데이터를 여러 서버에 분산시키는 것이 용이함
- 모든 데이터를 저장할 때, 데이터를 고속으로 처리할 때, 데이터에 대한 캐시가 필요할 때 유용함
NOSQL 단점
- 각 솔루션의 특징을 이해해야 하고, 새로운 기술로 운영 노하우가 적다
- 버그가 상대적으로 많다
- 업체마다 고유의 특색을 살린 NOSQL을 개발해 공개하는 경우가 많아 새로운 솔루션이 계속 출시된다.
MongoDB 소개
- Humongos라는 회사의 제품명이었으며, 현재 10gen으로 회사명이 변경되었다. 즉, 10gen사에서 개발한 솔루션이 MongoDB라는 뜻
- Key-value와 다르게 여러 용도로 사용이 가능(범용적)하고, 스키마를 고정하지 않는 형태라 스키마 변경으로 오는 문제가 없다.
- 데이터를 구조화해 json 형태로 저장하고, join이 필요없도록 데이터를 설계한다.
MongoDB 특징
- 메모리맵 형태의 파일엔진 DB이기 때문에 메모리에 의존적이고, 메모리를 넘어서는 경우에 성능이 급격히 저하된다
- 쌓아놓고 삭제가 없는 경우(로그 데이터, 이벤트 참여 내역, 세션)가 적합하고, 트랜잭션이 필요한(금융, 결제, 빌링, 회원정보) 경우에는 부적합하다.
- DBMS 랭킹에서 높은 순위를 기록하고 있으며, 2020년 개발자들이 가장 원하는 데이터베이스에 선정되기도 했다.
JSON 표기법
- 각 객체는 중활호({, })로 시작하고 끝남
- 문자열과 값으로 구성되어 있고 콜론(:)으로 구분
- 각 멤버들은 콤마(,)로 구분
- 값은 object, string, number, array, true, false, null 사용 가능
- 문자의 경우에는 따옴표를 사용하고, 숫자의 경우 따옴표를 사용하지 않는다.
- 배열의 경우 대괄호([, ])로 시작하고 끝나며, 각 값은 콤마(,)로 구분한다.
{
"firstName" : "John",
"lastName" : "Smith",
"address": {
"streetAddress": "21 2nd Street",
"city" : "New York",
"state" : "NY",
"postalCode": 10021
},
"phoneNumbers": [ "323 555-8152", "763 852-4653"]
}
MongoDB 장점
- Schema-less 구조: 다양한 형태의 데이터 저장 가능, 데이터 모델의 유현한 변화 가능
- Read/Write 성능 뛰어남
- Scale Out 구조(장비를 추가해 확장하는 방식): 많은 데이터 저장 가능, 장비 확장이 간단함
- JSON 구조: 데이터 직관적 이해 가능
- 사용방법 쉽고, 개발이 편리함
MongoDB 주요기능
1. MongoDB 인덱스
- 다수 인덱스 설정 가능
- 복합 인덱스 지원
- 빠른 검색 지원
- 도큐먼트에 저장된 데이터와 중복 저장 문제 발생
- 메모리가 부족한 시스템에서는 검색 속도 저하 문제 발생
2. MongoDB 복제
- Master-Slave 구조로, 데이터 복사본을 Slave에 설치
- Master 장애에 따른 데이터 손실 없이 Slave 데이터 사용가능, Slave에서 Master를 선출해 중단없는 서비스가 가능
- 데이터 손실을 최소화하기 위해 저널링 지원(MongoDB의 데이터 변화에 따른 모든 연산에 대한 로그를 적재)
3. MongoDB 샤딩
- 대용량의 데이터를 저장하기 위한 방법으로, 소프트웨어적으로 데이터베이스를 분산시켜 처리하는 구조이다.
- 샤딩 방식은 데이터베이스가 저장하고 있는 테이블을 테이블 단위로 분리하는 방법으로, 테이블 자체를 분할하기도 한다.
- 분산 데이터베이스의 전통적인 분할 3계층(응용, 중개자, 데이터계층) 구조를 지원, 응용 계층은 데이터에 접근하기 위해 중개자를 통해 모든 데이터의 입출력을 처리, 추상화된 한개의 데이터가 존재하는 것처럼 운용한다.
MongoDB 개발 환경
- MongoDB는 총 4개의 운영체제를 지원하는데, 대부분의 유저 90%가 리눅스를 사용한다.
- 빅데이터 처리를 위해서는 많은 수의 머신이 필수적으로 필요한데, 운영체제에 대한 비용이 상대적으로 적은 리눅스를 사용하는 것이다.
- MongoDB의 철학은 '메모리 관리는 운영체제에 맡기자'.
- 지원 언어:
- Java, JavaScript, Perl, PHP, Python, Ruby, Scala, Erlang, Haskell
- 윈도우용 MongoDB는 설치 및 사용이 간편하다는 특징이 있다.
MongoDB 깔기: https://www.mongodb.com/try/download/community 사이트에 들어가서 MongoDB Community Server를 다운로드 한 후, 아래와 같이 환경변수를 추가하자.

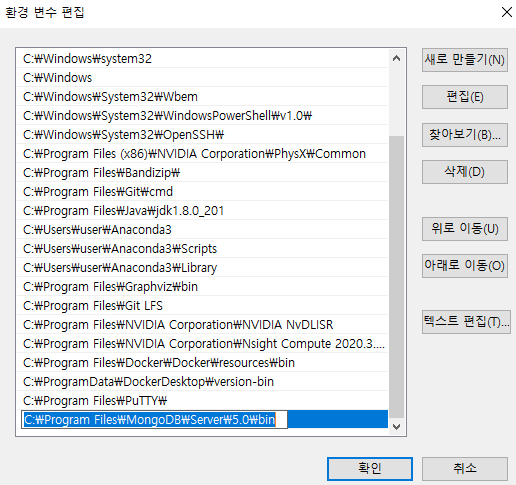
MongoDB의 이론과 실습을 위한 기반을 마련했다.
'개인 공부용' 카테고리의 다른 글
| MSA Design Pattern (0) | 2022.10.29 |
|---|---|
| hadoop 맵리듀스 실습 기록용 (0) | 2022.10.21 |
| hadoop 실습 기록 (0) | 2022.10.20 |
| hadoop 설치(기록용) (0) | 2022.10.20 |
| mongoDB 특징과 집계 정리 (0) | 2022.10.19 |